We tried granular recovery and full VM recovery on Hyper-V with Nakivo, in this article we will try to recover parts of clustered environments. I have two DCs for the domain, I also configured DFS for File Sharing, DAG for Exchange and Always-ON for SQL – all on Hyper-V. Let’s see how these environments fare on Nakivo.
Before we begin
Nakivo supports Hyper-V Failover Cluster backup – https://www.nakivo.com/blog/nakivo-v7-1-hyper-v-failover-cluster-support/
Hyper-V Failover cluster support for backup is great, but what about cluster aware backup for Windows services (DFS, ISCSI…), Exchange and SQL?
In Nakivo, there is no cluster aware backup support for services inside Windows Server like in Microsoft DPM for example.
DPM can recognize that your SQL is in cluster, or Exchange has DAG, but DPM also has agents installed inside VMs, while Nakivo is image based (and app aware) agentless backup solution.
Proper support for Hyper-V failover cluster is huuuge feature, since I witnessed backup solutions messing up snapshots of Hyper-V clusters. But I won’t be covering Hyper-V failover cluster backup in Nakivo, since it is pretty straight forward and simple.
What I’m interested in today, can clustered services inside VMs be recovered with Nakivo?
LAB setup
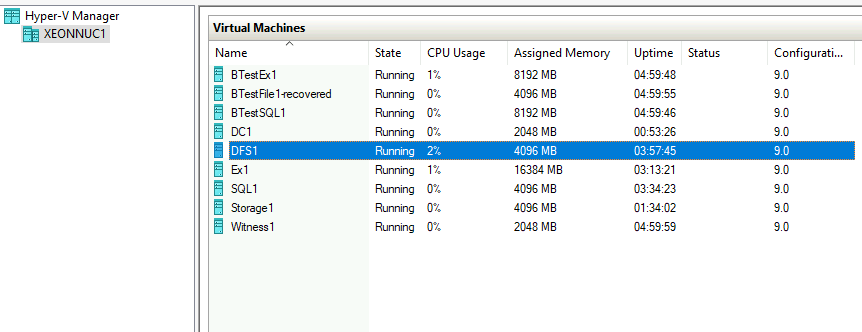
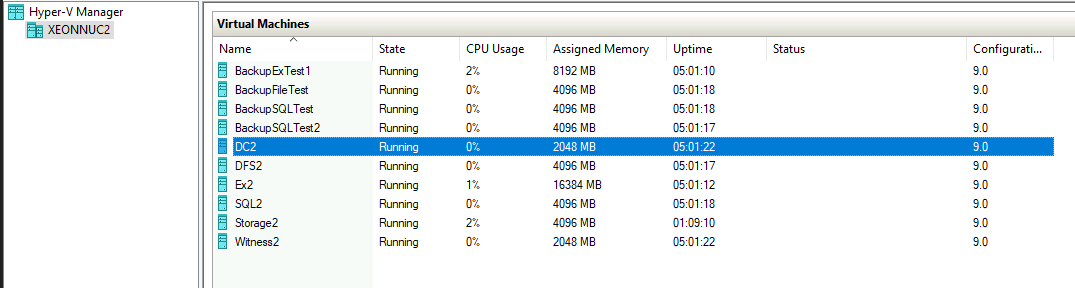
I have two Hyper-V hosts. XNUC1 and XNUC2.
Active Directory
On XNUC1 I have DC1, Domain Controller for the domain informatiker.local – it has counterpart on XNUC2 named DC2.
File cluster
DFS1 is also on XNUC1 and it is DFS cluster for my File share. It has also pair of its own on XeonNUC2 – DFS2.
Exchange cluster
Ex1 on XNUC1 is Exchange server which has DB1 inside DAG cluster with Ex2 on XNUC2
SQL cluster
SQL1 has two DBs inside Always-On availability group.SQL2 on XNUC2 has identical copy of the databases.
Storage replica
At last, we have Storage1 and Storage2 servers which host Storage Replica and ISCSI Target cluster.
Cluster witness shares
Witness1 and Witness2 are machines that hold file share witnesses for the clusters. We will not be toying with these today, because they are not inside cluster, and if those machines fail we can recover them from simple backup, or simply recreate Witness shares if the rest of the cluster is intact.
We will be simulating failure of the XNUC1 server. For this case I already have prepared backups of selected VMs on my Nakivo backup machine.
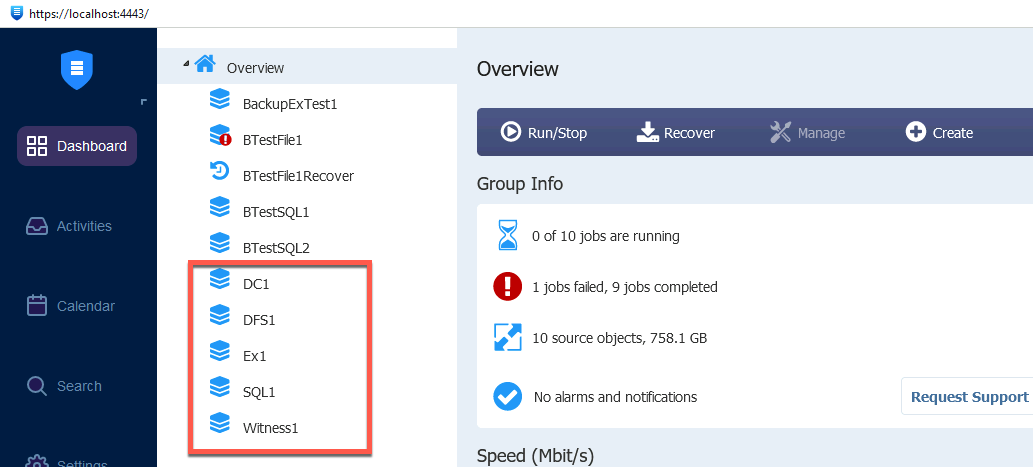
Those of you who are still following the setup will notice that there is no setup for Storage1 VM – we will get to that.
I will explain my simulation for every scenario when we start.
Please, don’t take this one on my word, simulate in your environment, and see if this scenario works for you and test services in depth. Test it well, and if it make sense, then go ahead with production backup plan.
Ok, let’s go.
Failure/Recovery Scenarios
I will be testing all the scenarios with the following method. I will power down VM on XNUC1 and delete it (physically delete it also). After that I will make small change to the corresponding clustered VM on XNUC2. After that we are going to restore VM to the XNUC1 and see if the changes replicate from XNUC2 to XNUC1. I hope it makes sense. Let’s see this scenario in action.
I won’t go into in depth testing of services and all the possible checks, because this would turn into a small book, and not simple guide.
Active Directory
This scenario assumes there was no corruption inside DCs and that there is only simple failure of the VM or server which is hosting DC VM. If there is some kind of corruption inside Active Directory and it is domain wide and already inside your backups – this won’t help you, you need different approach for your domain recovery then!
My DC1 and DC2 have sound connection without errors between them.
Replication status of DCs is without an error.
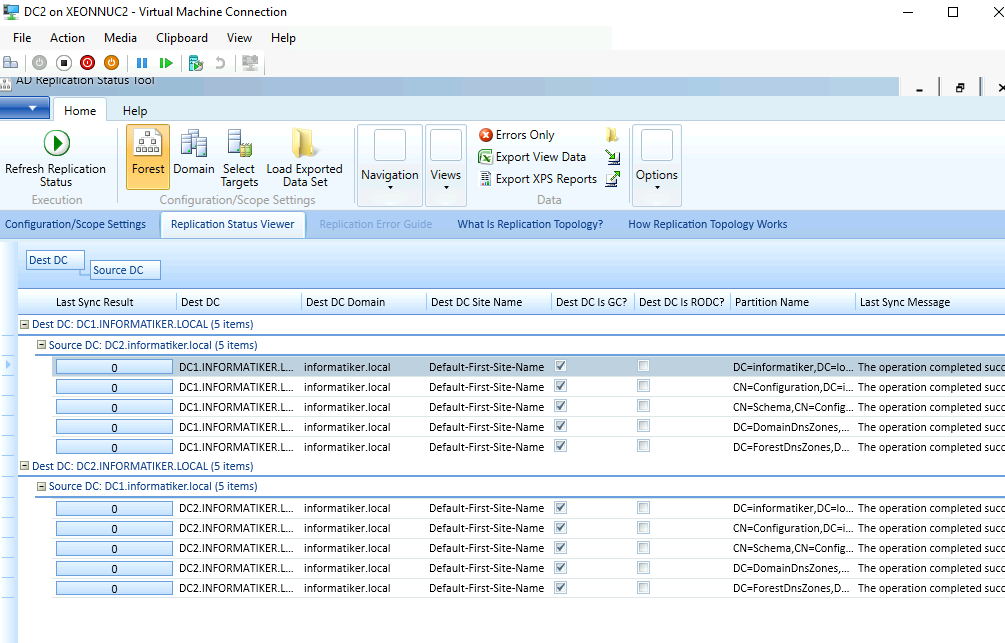
I did planned shutdown of DC1 and deleted the machine.
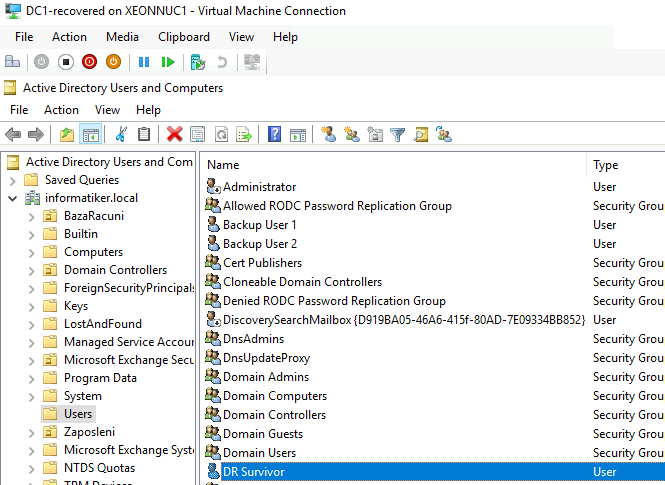
Now, ,on DC2 which remains active, I will add new user account – DR Survivor. User DRSurvivor does not exist in the backup I will restore.
Ok, now we will trigger full VM recovery for DC1 from Nakivo backup – I already got that scenario covered for Nakivo, so be sure to check it out, I will not go through detailed steps here.
Recovery finished with success
Let’s start recovered VM and hope for the best
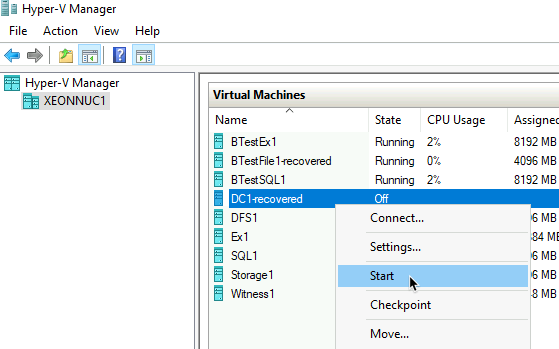
After VM booted everything was in place, even network setup…
After some time I tried replication test – it went without error!
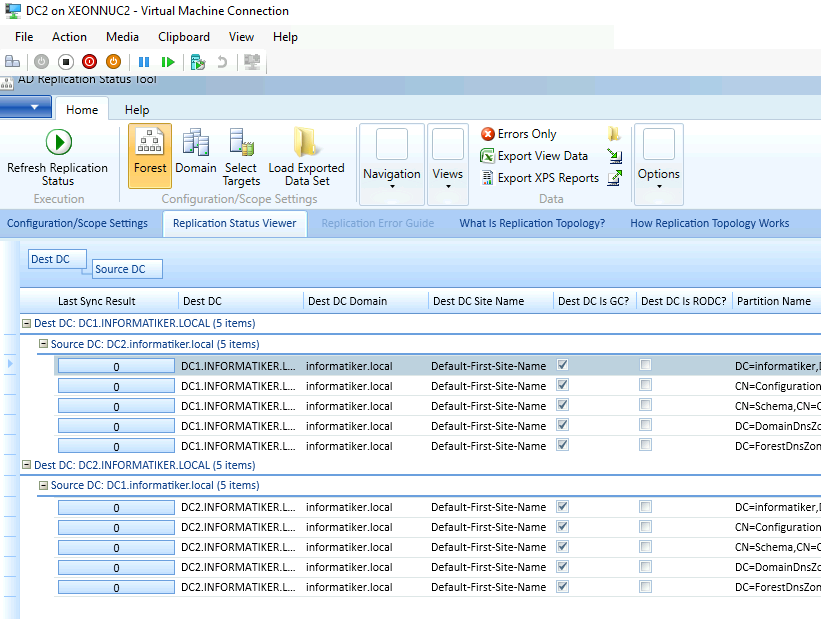
DR Survivor is also visible on DC1
Ok ,so this quick test shows that DC1 although deleted and then recovered from backup is intact. There are many other tests that can be done on DCs to see if they are sound and healthy. Again, if there is some kind of corruption inside your active directory, and within backups, this won’t resolve your issues.
File server cluster
Next up, we have DFS1 and DFS2 VMs which are in cluster and have network file share activated and replicated between them.
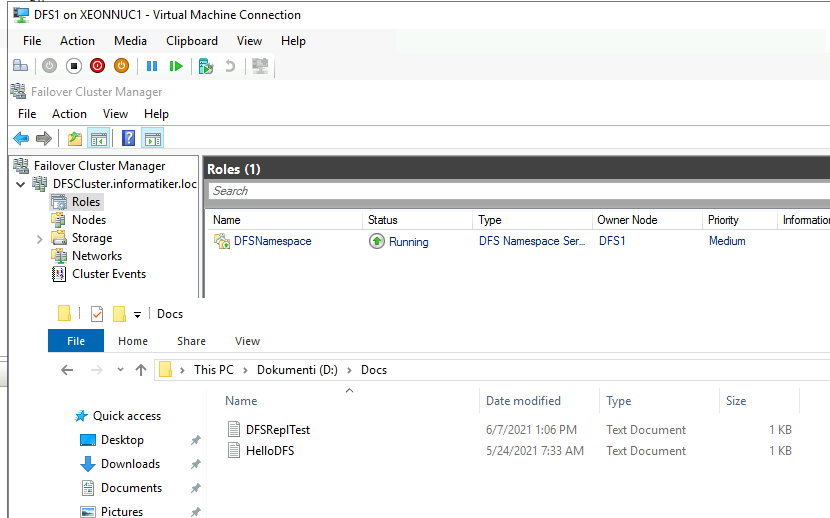
Ok ,I will turn off (gracefully) DFS1 and delete it.
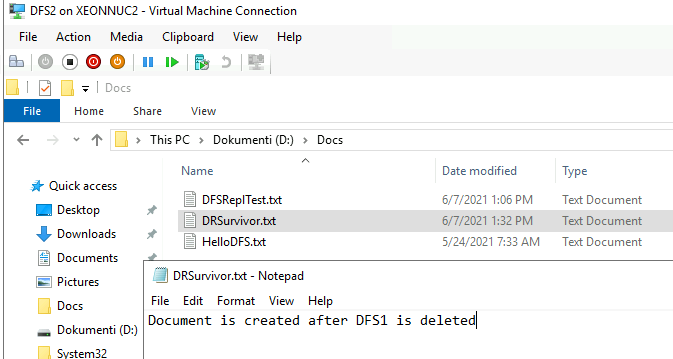
After I deleted DFS1, I went to DFS2 and creted new file named DRSurvivor.txt. If everyhing goes to plan, this document should replicate to DFS1 after we bring it back from backup. Document DRSurvivor.txt does not exist in the backup I will restore.
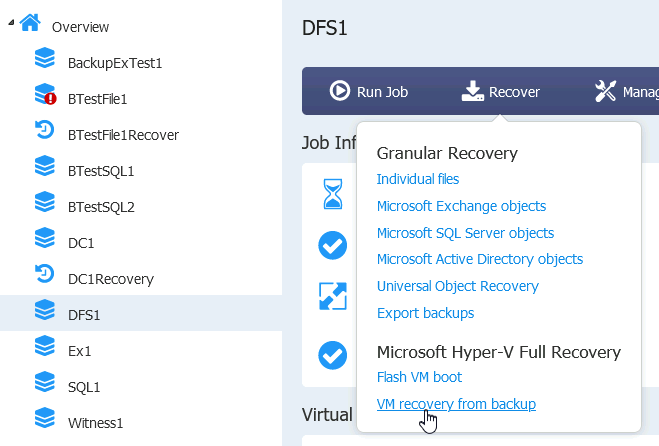
On Nakivo, we will again start VM recovery from backup
Let’s power up the machine.
It boots!
DRSurvivor.txt file was replicated but our cluster is down
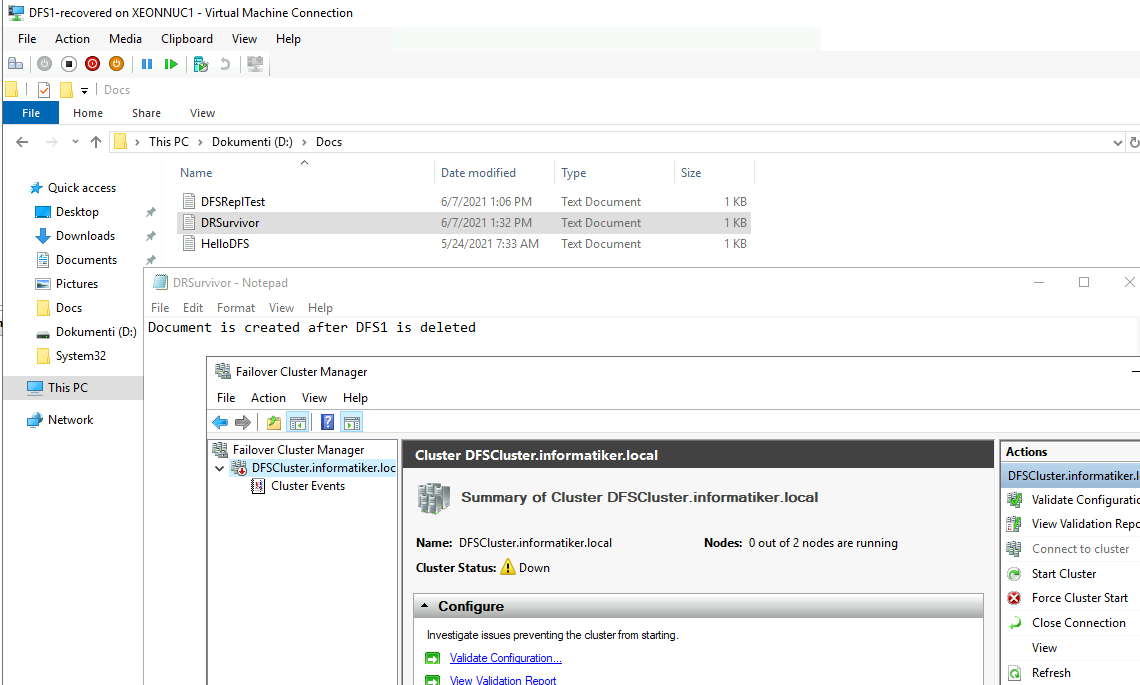
I will try to start it on DFS2.
It won’t start.
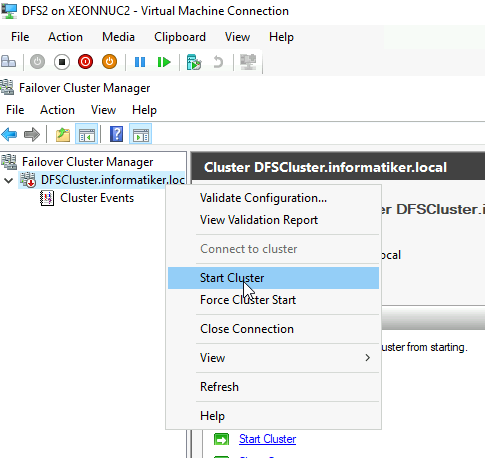
I rebooted both nodes, and then Started Cluster Service on both Nodes. Still no luck.

I will try to Force Cluster Start
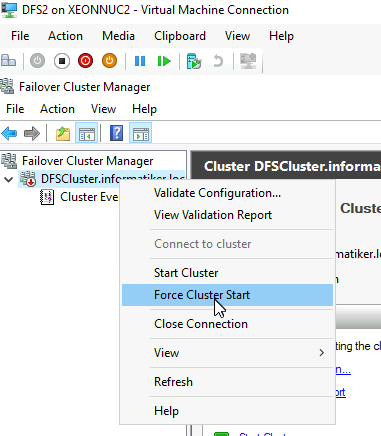
Huge risk, but hey, we are in dangerous situation.
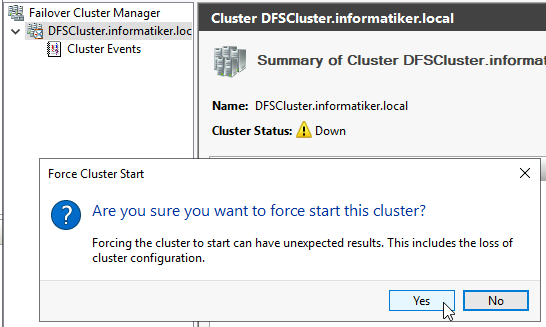
It works! We brought it up
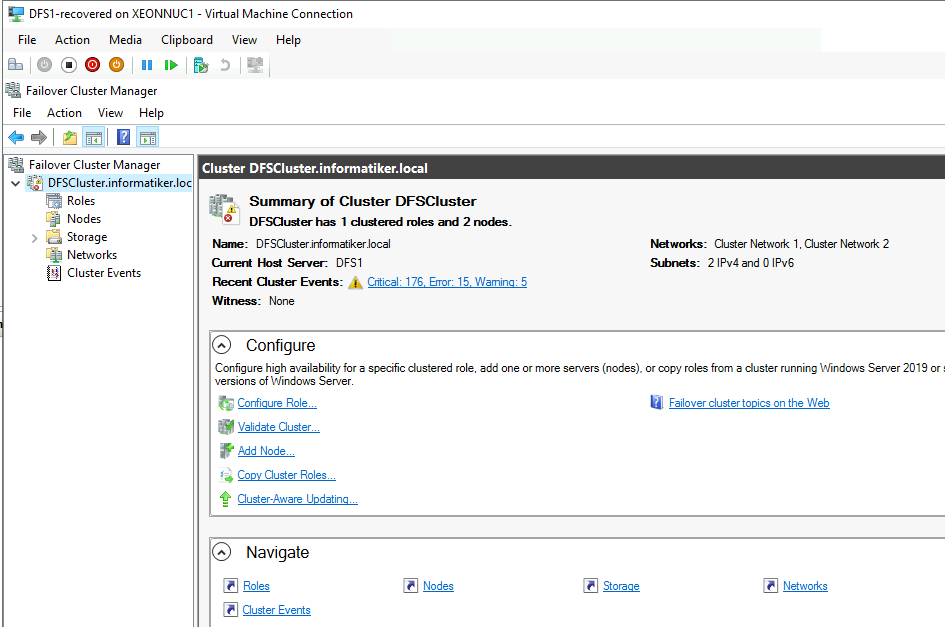
Don’t blame this one on Nakivo – it is my fault, I haven’t configured any type of witness in two node cluster and DFS1 haven’t transferred vote to DFS2, so this is why cluster was broken. You can expect this behavior if node isn’t gracefully shut down, and there are only two nodes in cluster.
You can read more about cluster quorum here – https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/understand-quorum
Anyway – file replication continued fine after this, I tested with few files created on DFS1 and then on DFS2.
Everything worked fine even after I rebooted DFS VMs, and also I was able to transfer role from one node to another without issues.
So, conclusion is – everything is fine – Nakivo is not to be blamed, it did well.
SQL Cluster (Always-ON)
Story is the same as in the case with AD and File server – I will delete SQL1 VM after I shut it down (gracefully). After that I will do some changes on SQL2 in DBs that are in Always-ON availability group.
Ok, so SQL1 VM doesn’t exist anymore
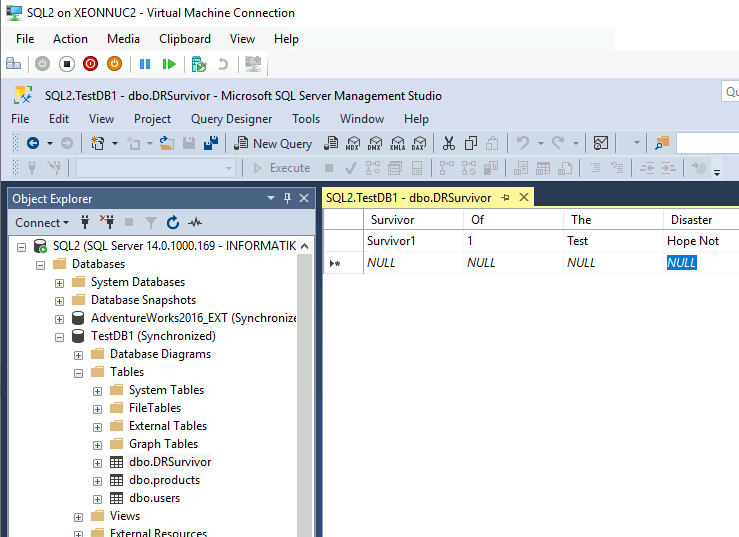
After I’m done with SQL1 machine, on SQL2 I will add another table into TestDB1 database. I will name it – DRSurvivor
Tables products and users already exist, but I added table DRSurvivor after SQL1 was deleted. Table DRSurvivor does not exist in the backup of SQL1.
Started the recovery…
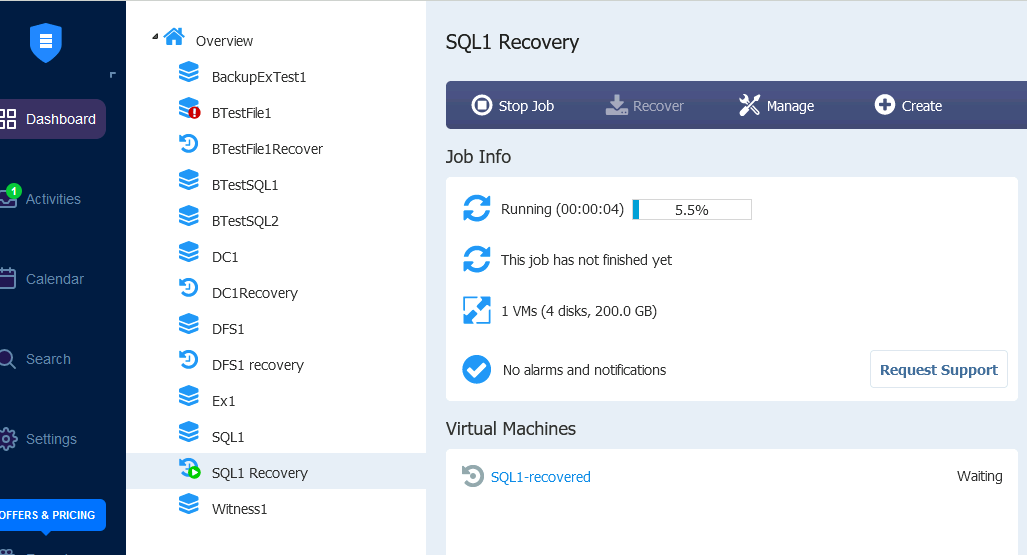
Recovery was success
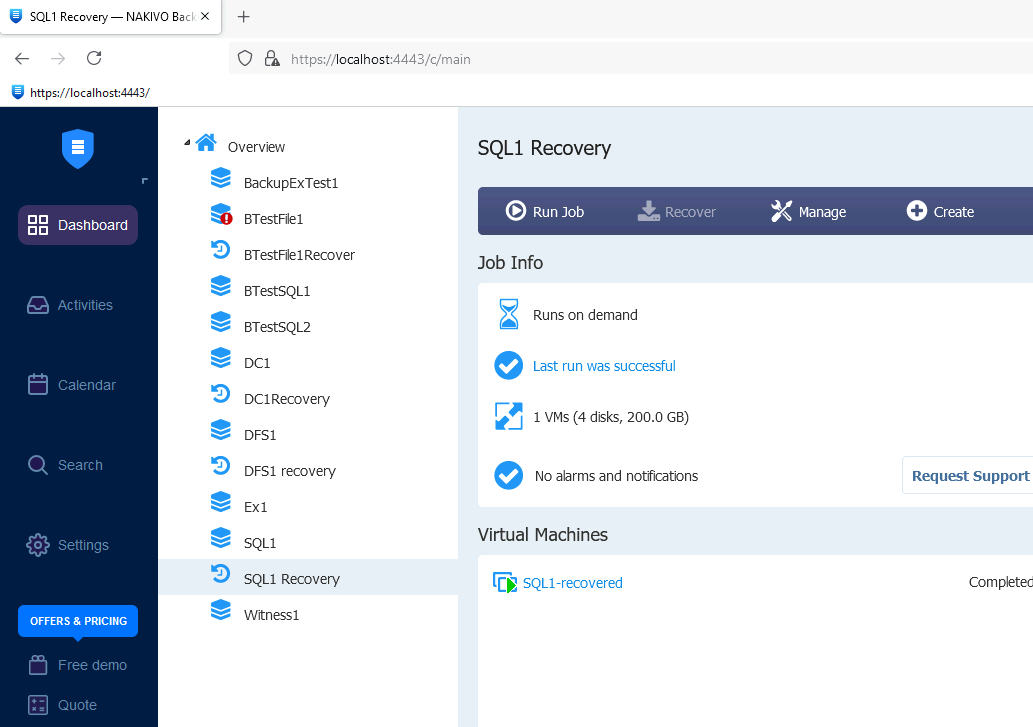
Recovered SQL1 machine booted, but TestDB1 is not synced.
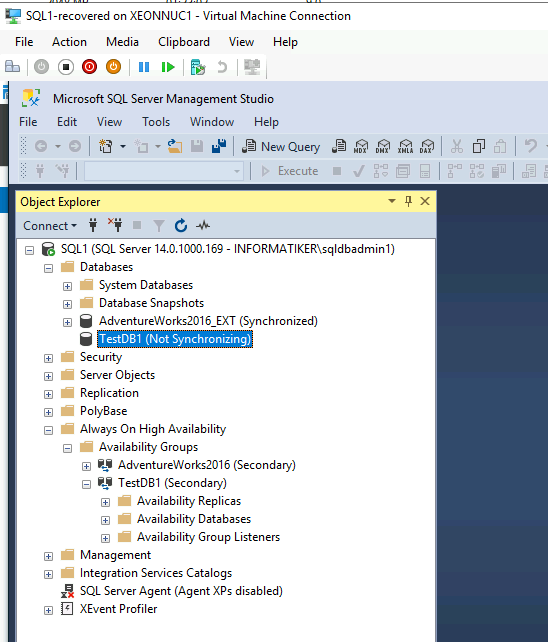
On SQL2 everything looks fine which is good for our situation, but SQL1 is not cooperating.
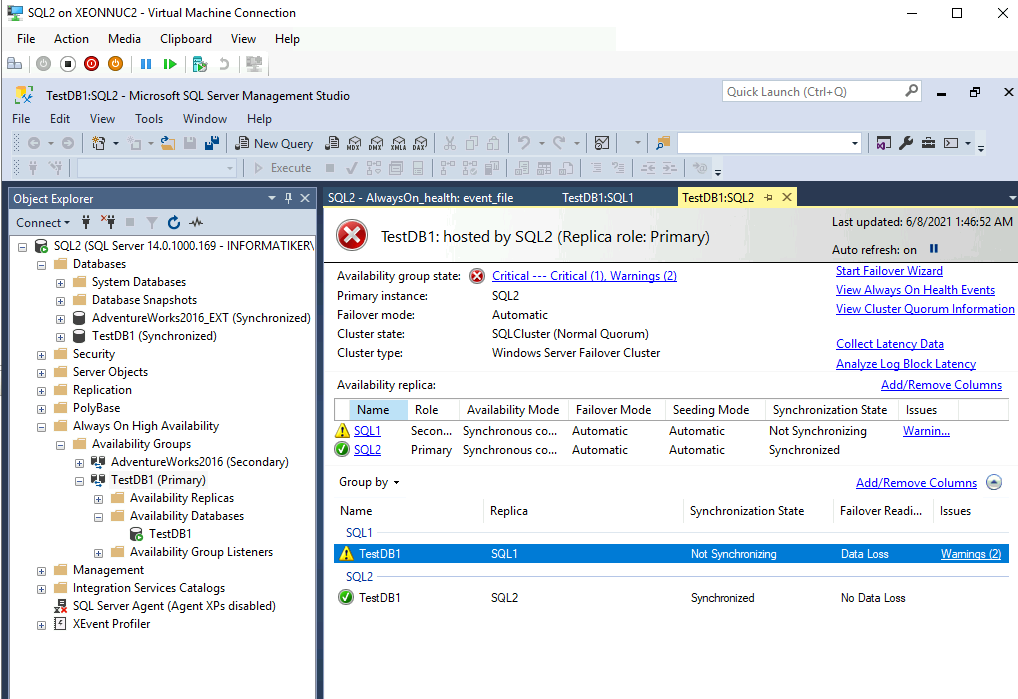
Back to the SQL1, TestDB1 is paused, I will select “Resume Data Movement”.
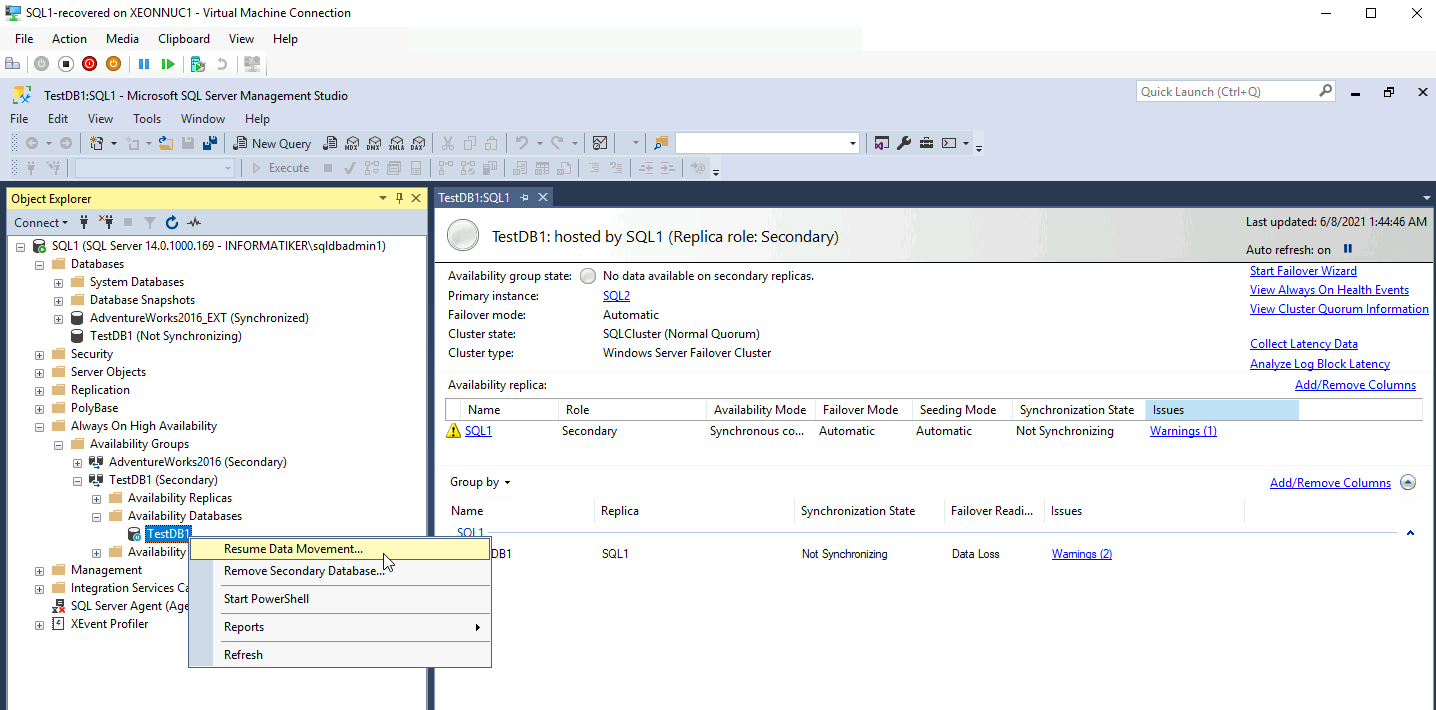
New window will pop-up – OK
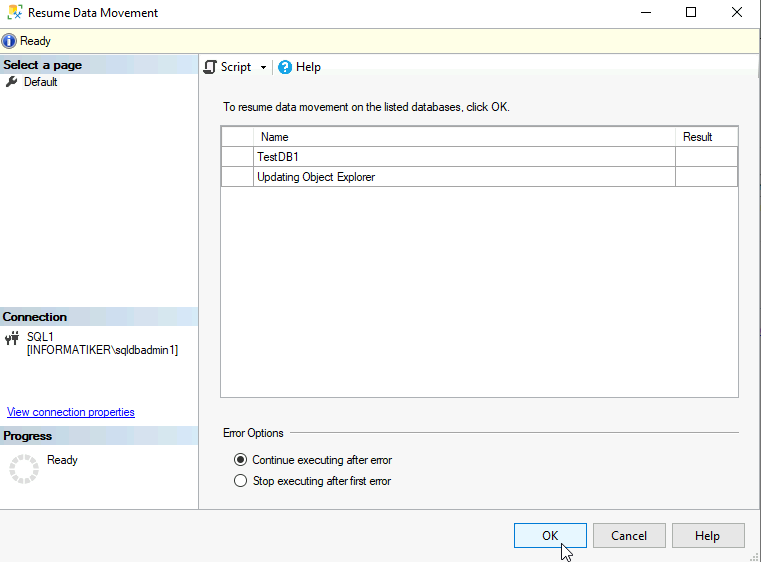
Error updating Object Explorer.
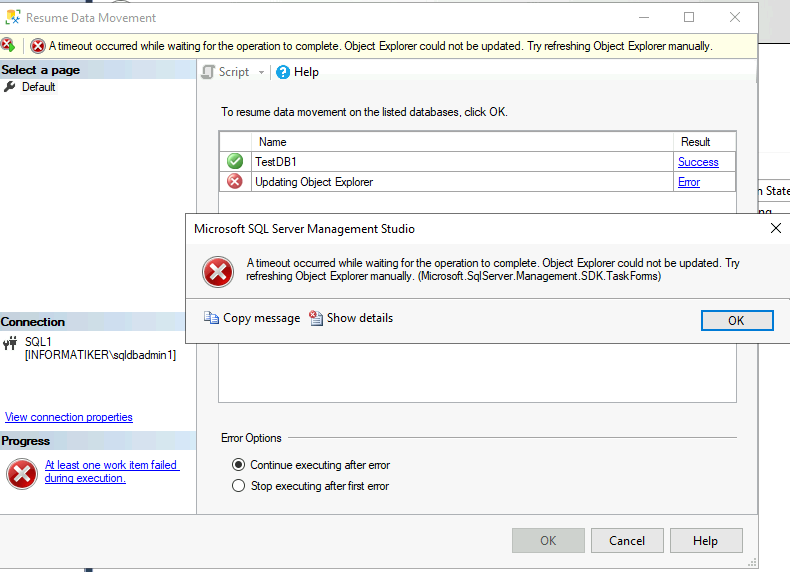
Ok, so replication won’t resume. If you have this situation in real life – I would suggest you first backup all the databases manually, before trying anything else, further down the line.
Since “Resume Data Movement” command finishes with “Object Error could not be updated” error, we have another option.
We will execute following query on SQL1, since that is the place where synchronizing is stuck.
ALTER DATABASE YourDatabaseName SET HADR RESUMENothing changed.
So, we are pretty much stucked and cannot elegantly just restore Always-ON HA. I won’t spend too much time on this problem here.
What I will say is that I simply deleted Always-ON availability group for TestDB1 on SQL1. I deleted it on SQL1, since SQL1 is secondary member.
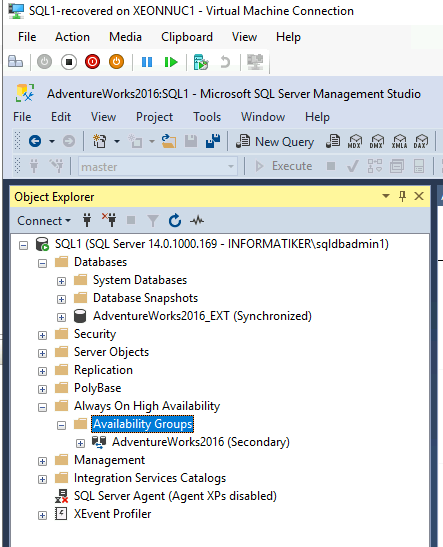
Soon after that, on SQL2 I refreshed state of the SQL in SSMS.
TestDB1 was in restoring state…
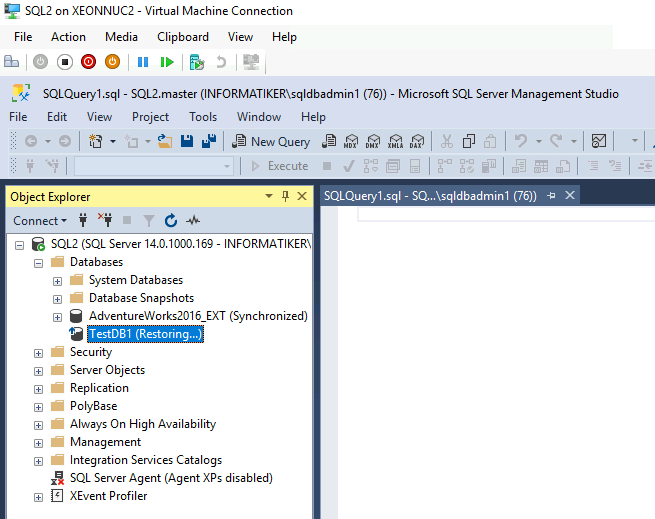
And it stuck in restoring state for almost an hour. Too much for DB of few MBs in size.
So, in the end I executed following command
RESTORE DATABASE databasename WITH RECOVERYAaand, database was available after that on SQL2.
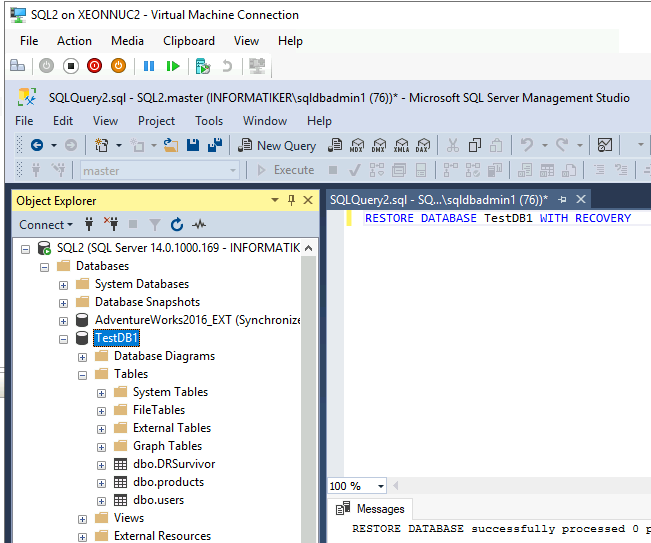
I checked the tables – data is fine.
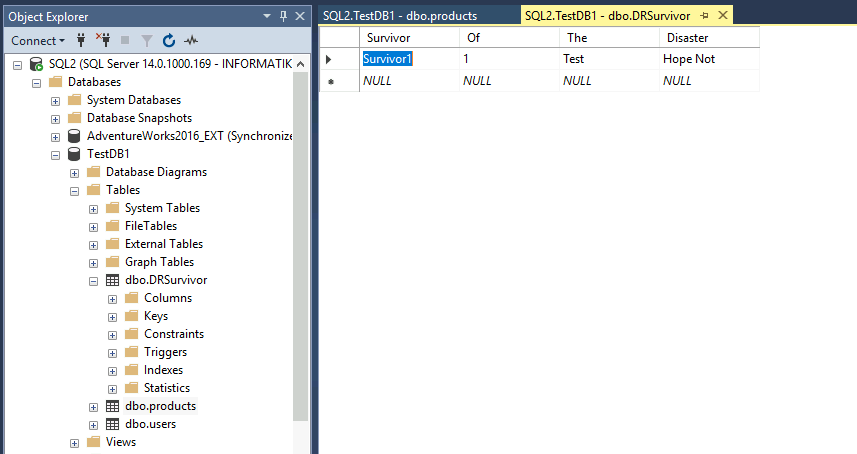
After that I recreated Always-ON cluster (started recreation process on SQL2 which has both databases intact) and everything is ok again. Failover works, data is intact.
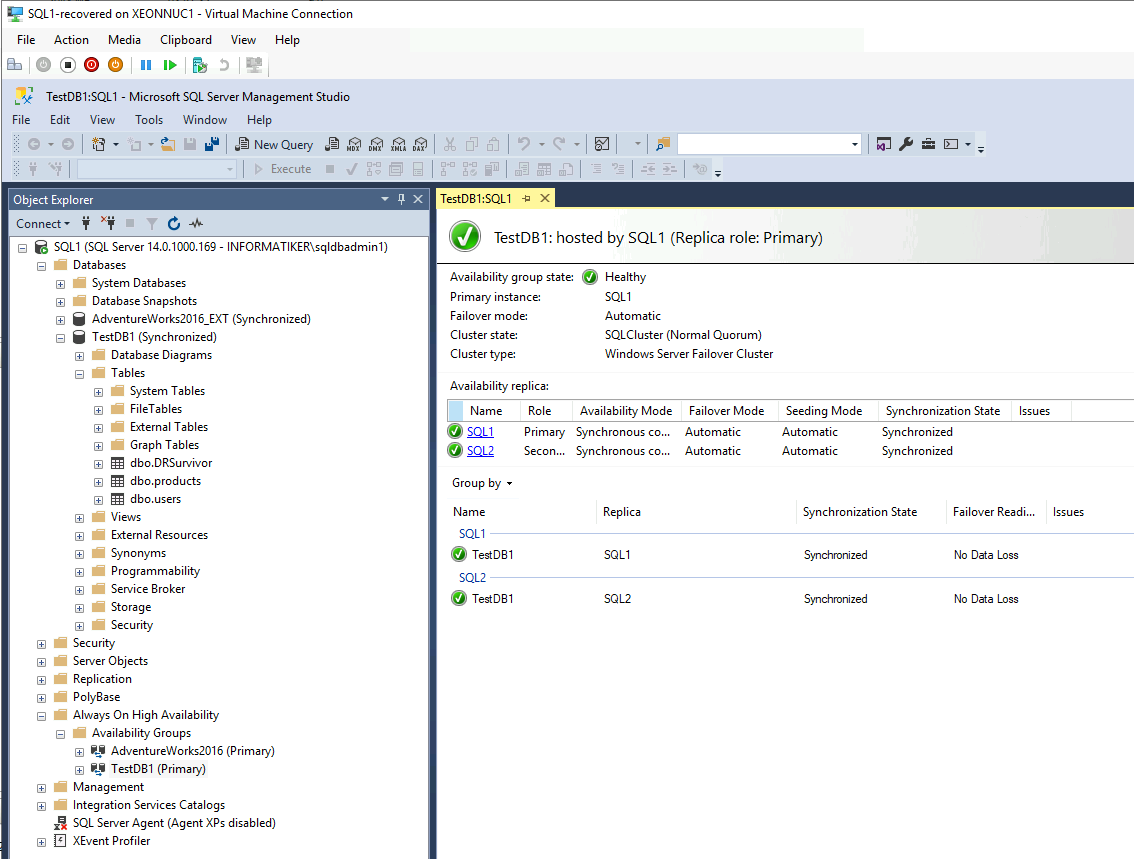
Again, recovery wasn’t painless, but, you need to take into account that there was some data that changed in between the period I deleted and restored SQL1.
I can’t really blame Nakivo for the mess, it did its work. And if it comes to worst, you can just extract database from the backup and restore it to the new machine.
Again, although SQL Always-ON haven’t completely worked after I restored SQL1, really can’t blame backup software for that. Nakivo has your data covered well, you can easily restore cluster or create new VM if you have data you can restore to it, after all information is the most important part here, and if we can save time by not recreating whole service that is also a nice bonus.
Exchange Server
DAG is set between Ex1 and Ex2 server. DB1 is inside DAG between these two servers.
I really cannot say I expect much from this, but let us try.
I will gracefully shutdown Ex1 server and delete it completely.
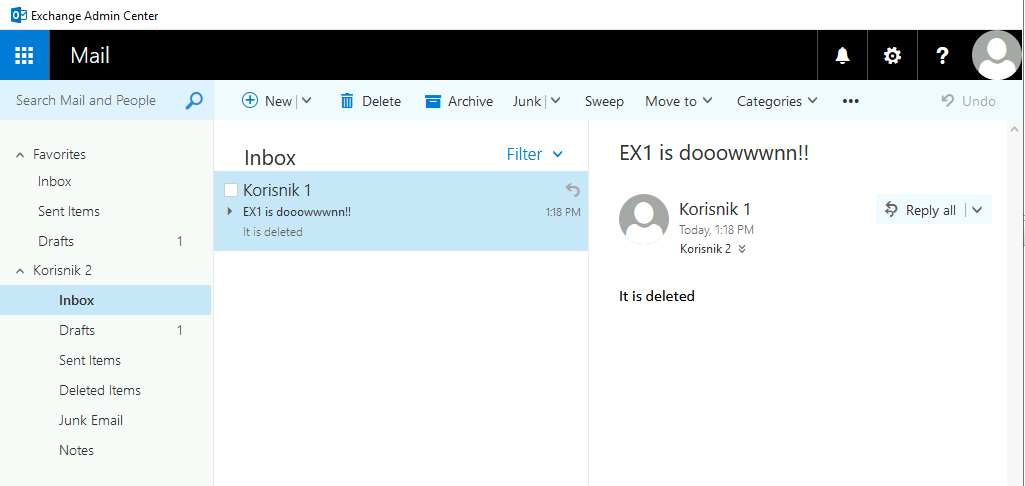
After I deleted Ex1, I went to login to Ex2 and send and simple email from one user to another (this email is not in the backup)
We will proceed to restoration of Ex1 from the backup on Nakivo.
Recovery is underway…
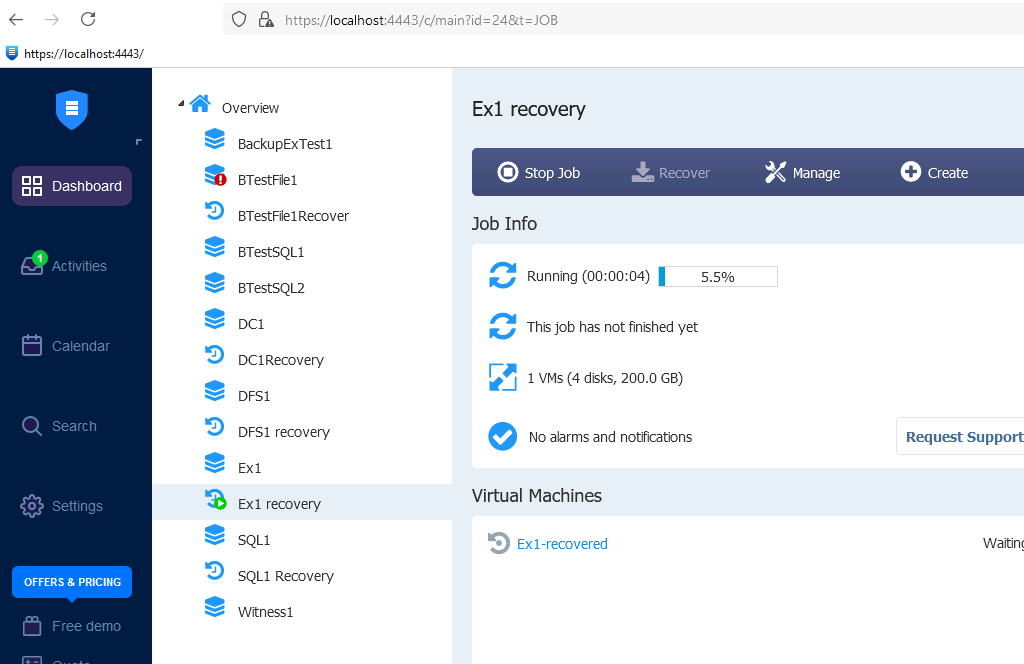
Recovery finished with success
VM booted with success, lets see now, if DAG works
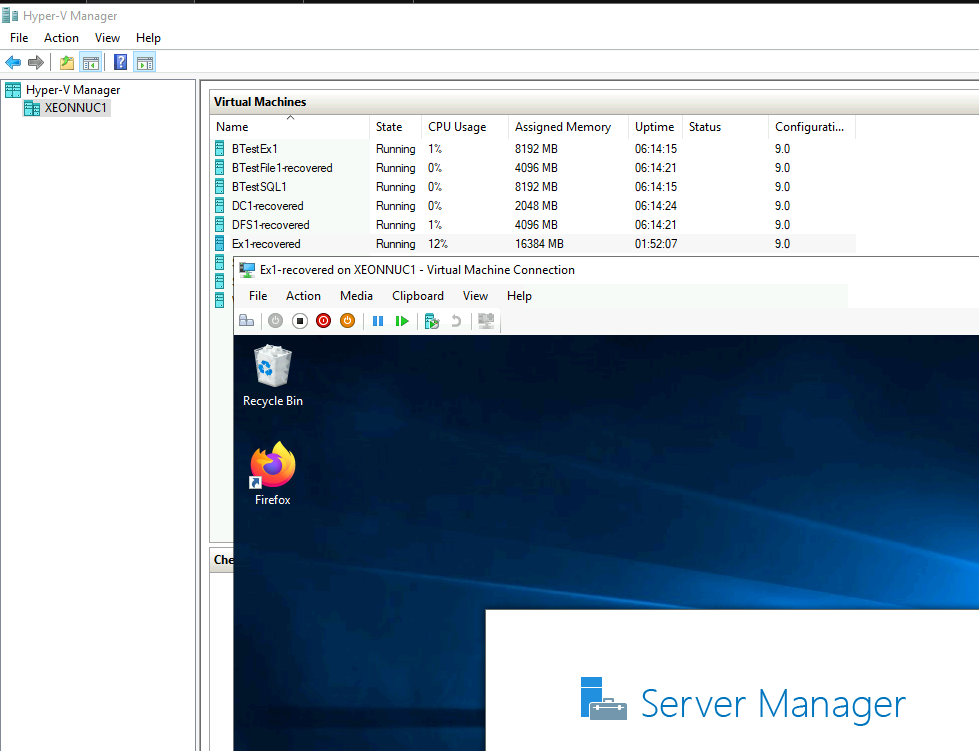
Database is mounted, active on EX1 I just recovered, and status is healthy for Ex2.
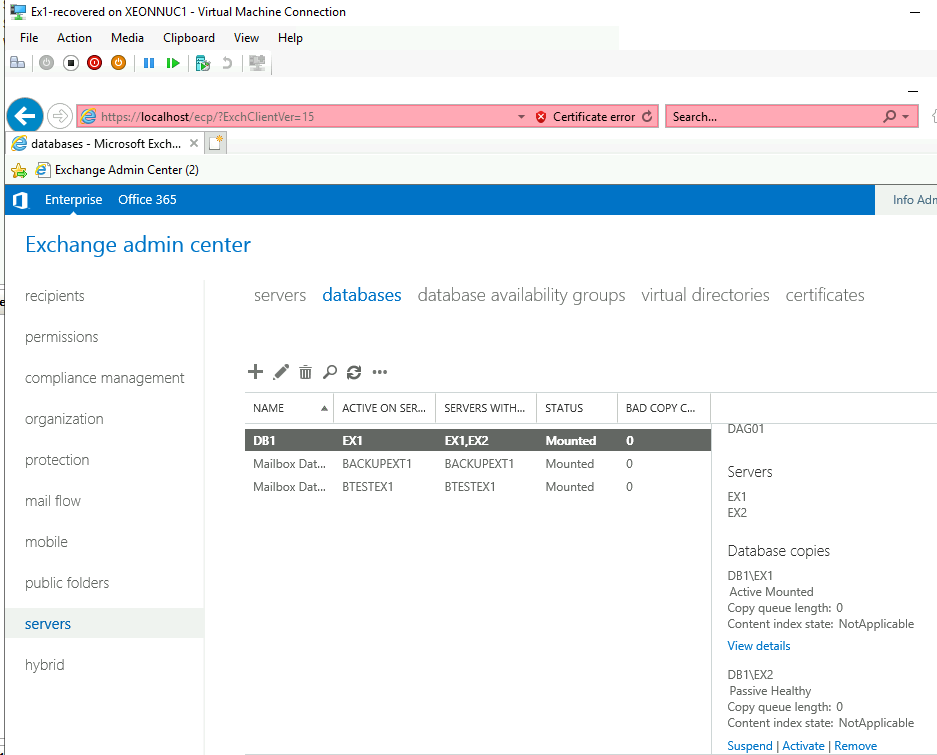
I turned off Ex2 server, and just tried simple things on Ex1 – everything works. All the emails are in inboxes of the users (even ones I sent while Ex1 was deleted).
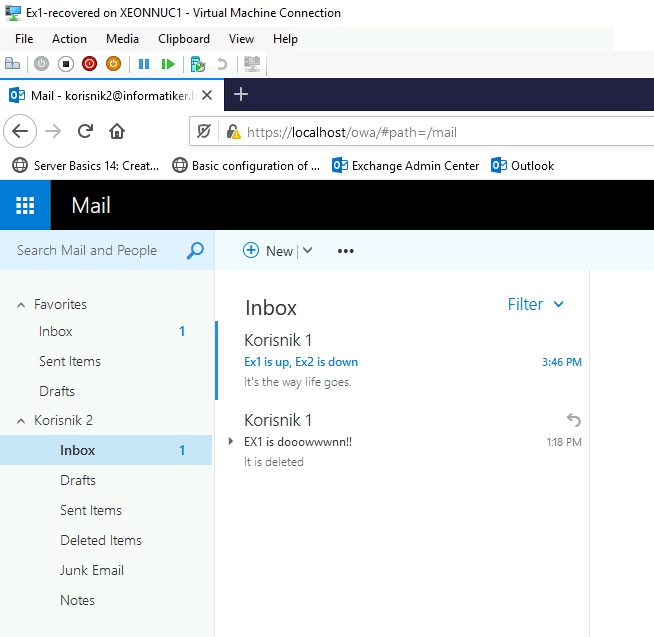
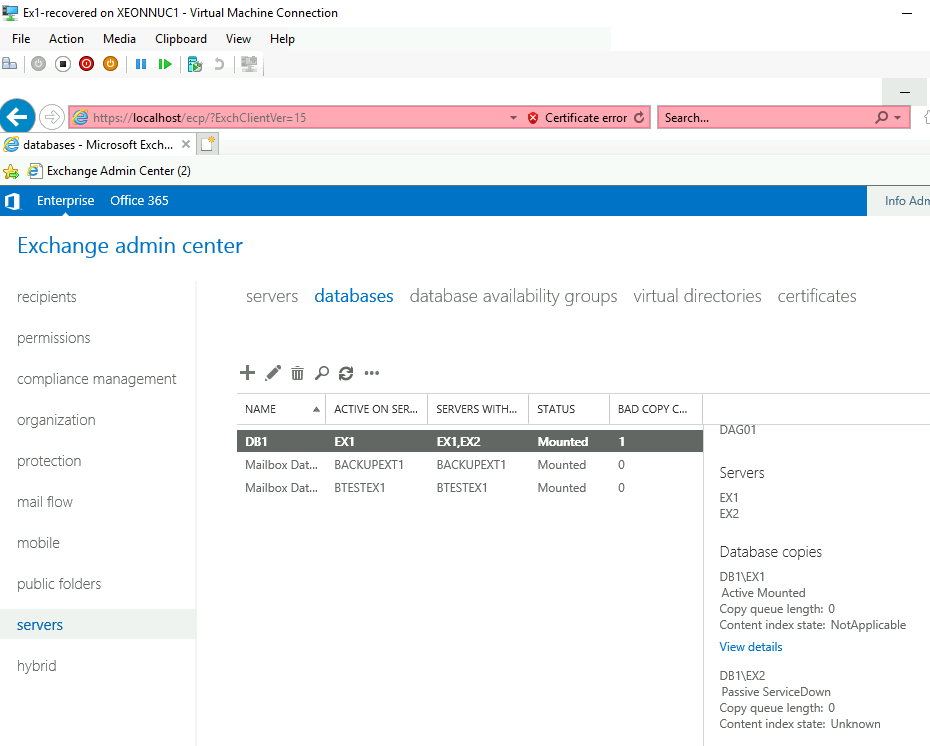
I tested every scenario – Only Ex1 up, then EX1 down, but Ex2 up, both servers up – DAG works, all mails and mailflow is intact.
So, scenario I feared most, turned out best.
Exchange works out of the box after it is recovered…
What we did so far?
Every machine with -recovered suffix was deleted and then recovered, we had no data loss, and we managed to recover all scenarios.
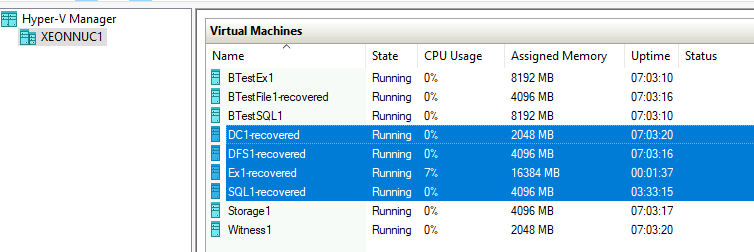
I did only services which are (in my eyes) crucial for every production system.
But there is one thing left – Storage Spaces with ISCSI Target I created.
Storage Spaces with ISCSI Target
I have two servers (Storage1 and Storage2) which are holding ISCSI Target cluster and Storage Spaces on them.
This whole LAB im testing Nakivo on is freshly installed on new Hyper-V host. So, all is done just for Nakivo testing.
Machines are exactly set as all the other machines in this lab.
But still, backup won’t work the same way. This is what I get when I try to backup if application-aware mode is on.
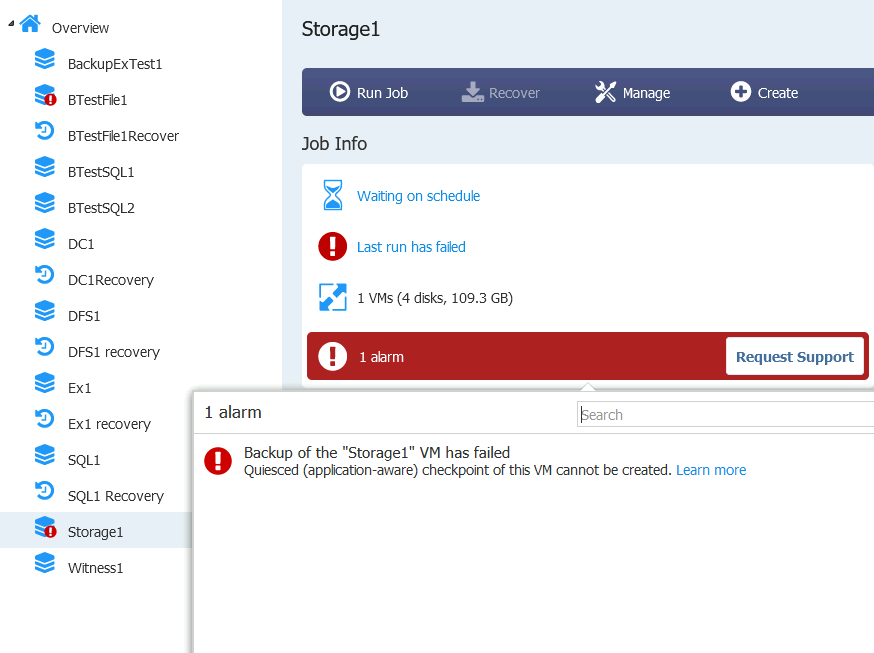
These are the settings for the backup job of Storage1
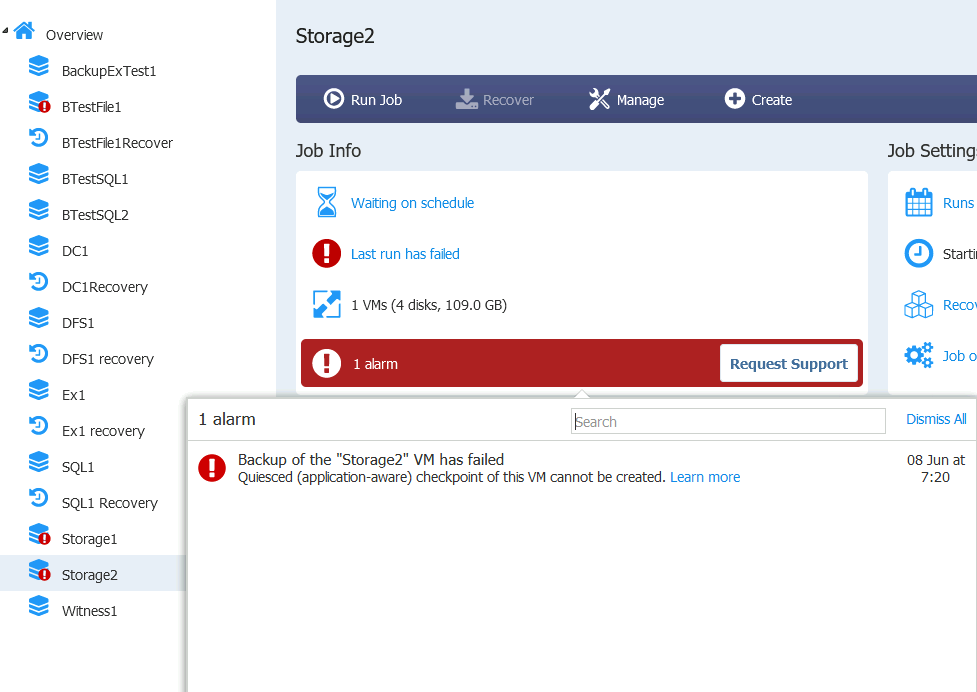
So, ok, maybe something is wrong with my XeonNUC1, let’s try to backup Storage2 VM which resides on different hardware.
Same error
Production checkpoints are turned on, everything is set the same as I described in my backup article for Nakivo.
I will try to run backup again for Storage1 VM, but with App-aware mode disabled this time.
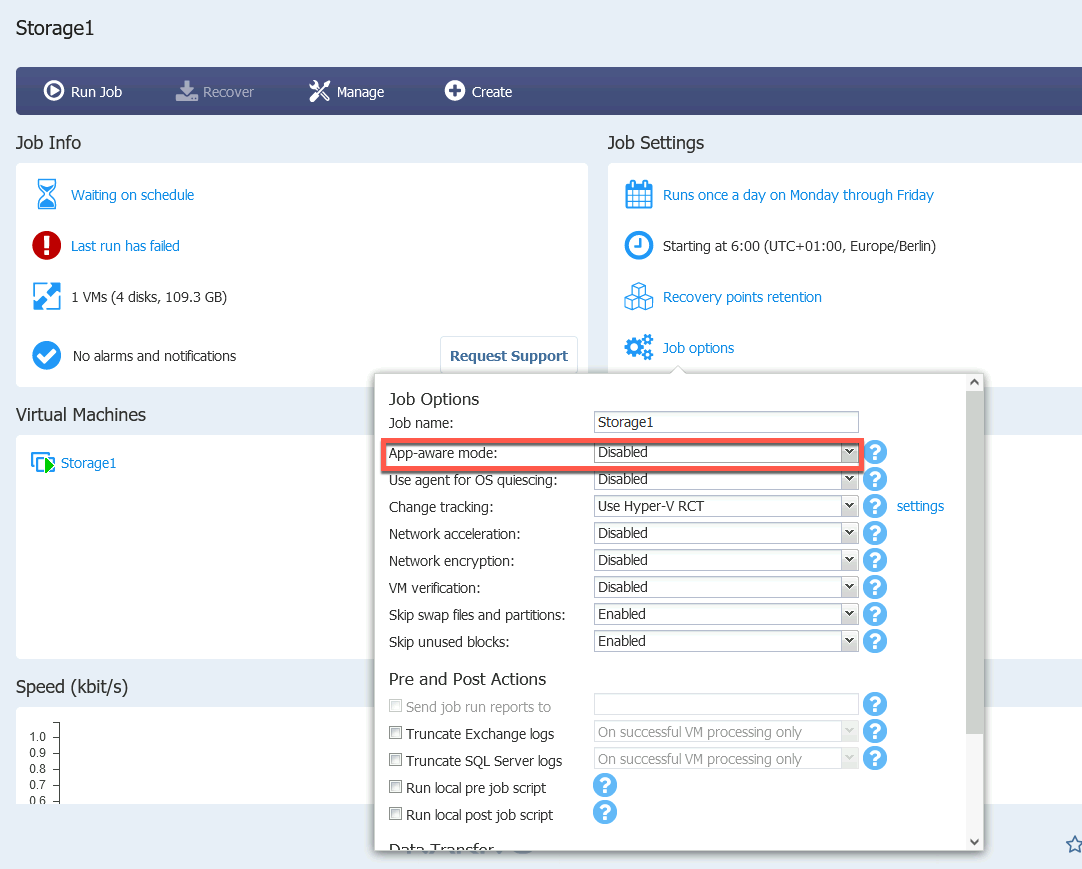
That one worked
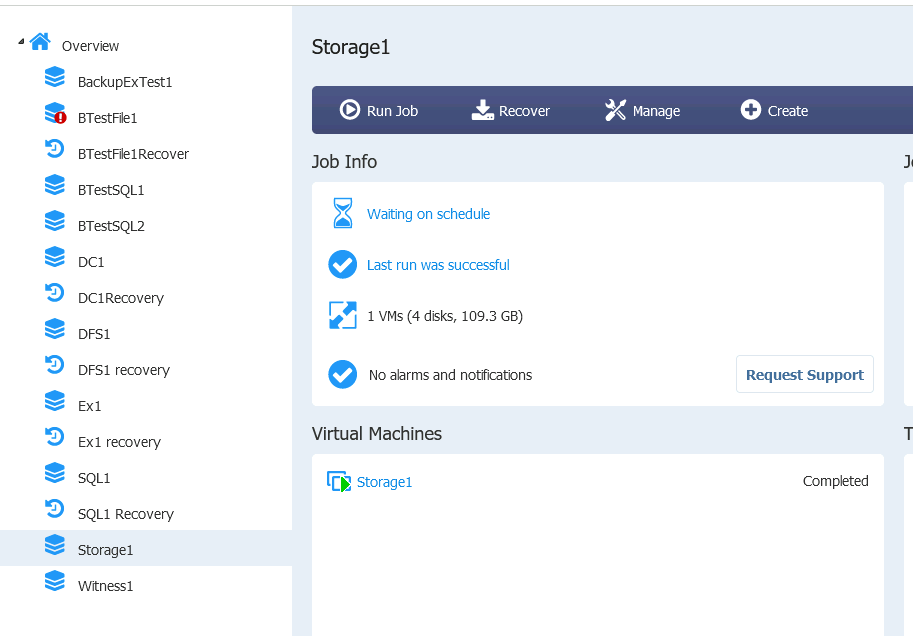
There is a problem with app-aware backup and storage spaces, and best way to go around it is to just backup VM without it being app aware.
Ok, now that we have backup, we will do the same as with every other process here – Delete Storage1 VM.
After we deleted Storage1 VM, I will just try to recover it. I don’t have any special ideas for editing on Storage2, let’s just see what happens after we restore Storage1 VM.
Restore was success
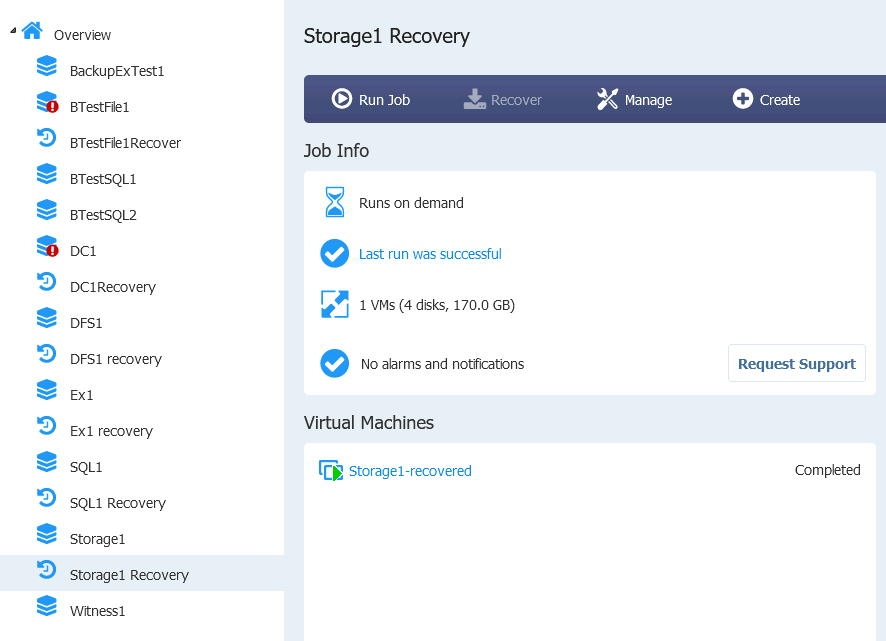
Machine booted and Cluster is working
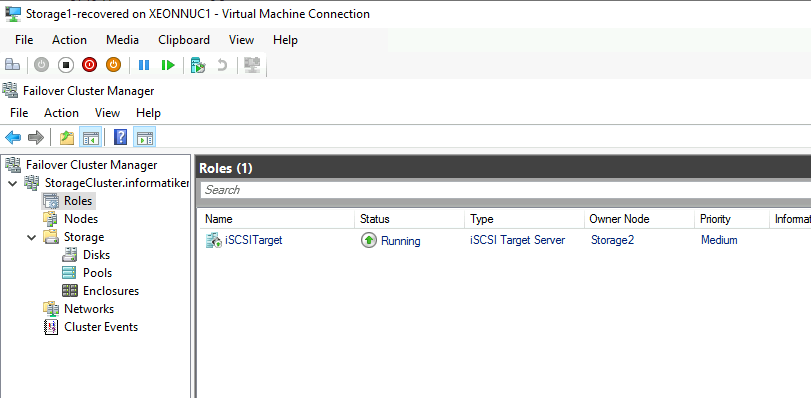
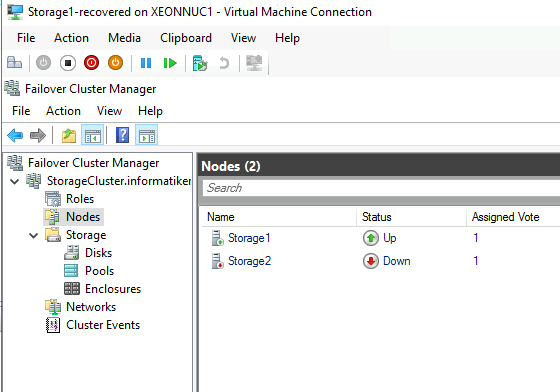
Again, I tested failover with one of the nodes down (Storagfe1 and Storage2) and both nodes up.
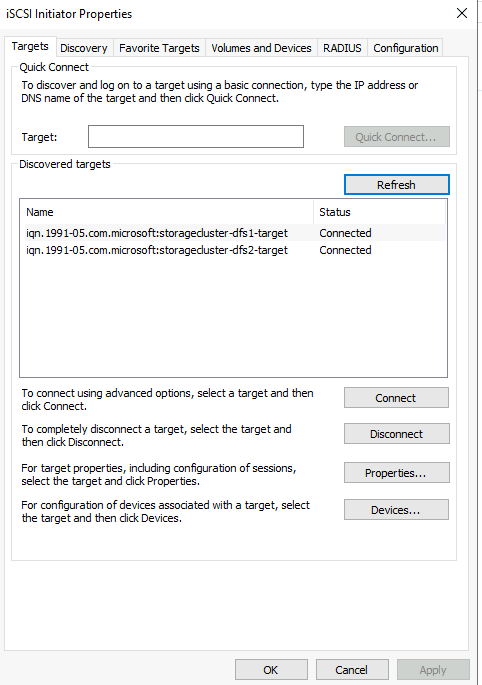
ISCSI Target services were up and running
In all scenarios I got working results, and Storage Spaces also fared well. There is no app-aware backup for S2D but as long as everything works, I don’t mind it.
Conclusion
Time to wrap this up, this guide is already too long wall of the text.
In the end we went through our entire lab, deleted VMs, and then recovered them. Ignore VMs starting with B and Witness machine, these are simple machines, done for simple tasks and backups.
All the machine with suffix -recovered were deleted and then recovered. All of these machines were in some kind of cluster/HA environment.
My conclusion is that Nakivo can get passing score for recovering clustered machines. Problems I had, that I described here are not fault of backup software, but rather system itself.
Only thing I would like to understand better is, what is the problem with Nakivo and Storage Spaces not being able to do app-aware backup, I will investigate that further when I have time.
In the end, all that matters is to get you data or DBs back, if you have knowledge, you can recreate cluster quickly.
Every machine that I backed, restored fine with all the data in place.
In the end, do your own homework, test everything throughout and make conclusion for yourself, what is fine and works for me, doesn’t have to be in your case. Every business is specific and has its own needs.