We went through a lot of abilities of the Nakivo software, today we will look into Disaster Recovery. We will setup Replication job with Nakivo for our Hyper-V environment.
Before we begin
We already went through installation, configuration, backup and recovery jobs for Nakivo, all of these articles are on my blog. Today we will be looking at Replication jobs for Nakivo.
Here are some links if you are interested to know more about this.
https://helpcenter.nakivo.com/display/NH/Disaster+Recovery
https://helpcenter.nakivo.com/display/NH/Creating+Hyper-V+Replication+Jobs
We will be doing VM Replication on Hyper-V.
You can also enabel Replication from backup jobs you already have, or enable Site Recovery, which enables you to automate DR. As I already said, we will be doing VM replication in this scenario.
Prerequisites
In my environment I have four physical NUC machines.
XNUC1 holds few machines – machines that are starting with B are single machines, these machines are not in any type of cluster and are available only on XNUC1.
Machines named DC1, DFS1, Ex1, SQL1 and Storage1 are all in some type of cluster. These machines have their pairs on another Hyper-V physical host named XNUC2.
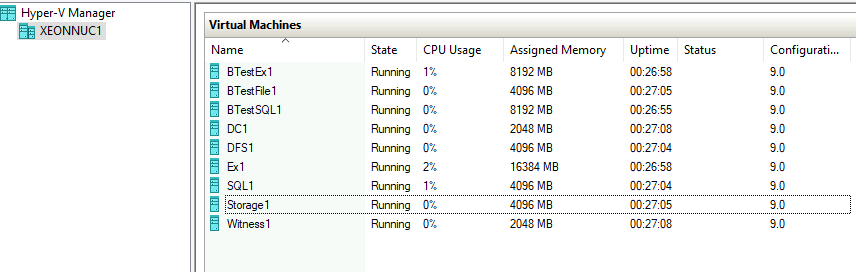
Here is XNUC2 with VMs on it. As, I mentioned, XNUC2 has machines which are in some type of cluster with XNUC1
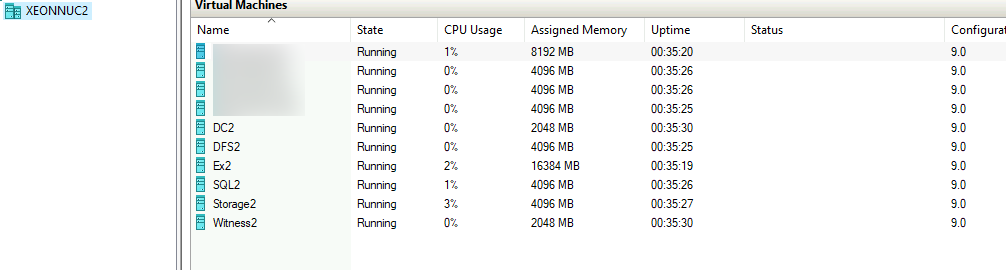
Machine named XNUC3 is empty Hyper-V host. This is the machine we will replicate to from XNUC1. XNUC2 will stay intact. We will only use it to test our cluster services.
Very important thing – XNUC3 has the same hardware configuration as XNUC1 – same CPU, same amount of RAM, same disk space and configuration, same Hyper-V network configuration. It is extremely important that hardware/software configuration is the same. If the resources are scarce on the machine you plan to failover to, then it does not make sense.
XNUC4 is holding Nakivo Backup.

Configuring Replication
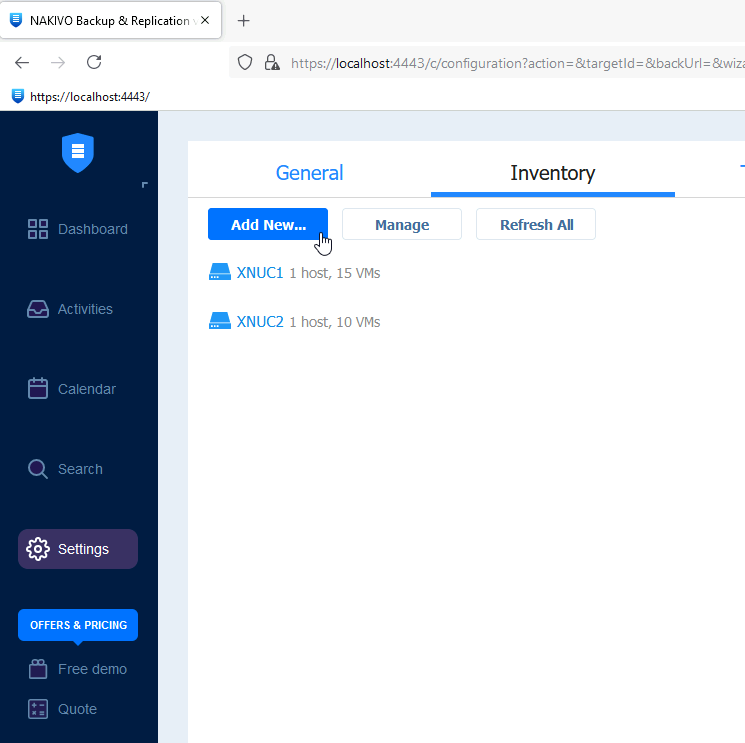
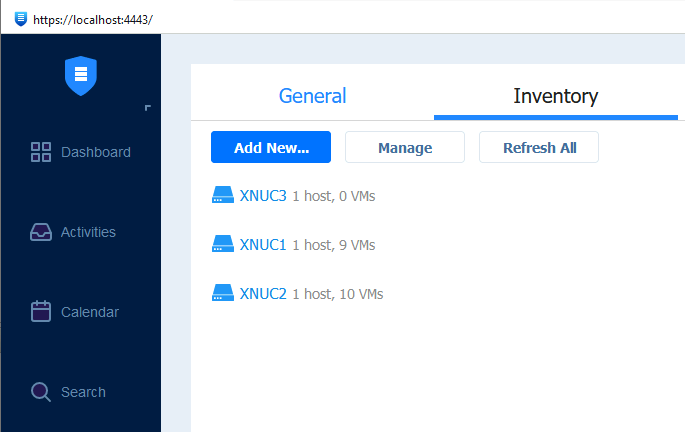
Before we start with the replication wizard, we will first go to our Nakivo Managament console to the Settings | Inventory tab | Add New
As you can see, only XNUC1 and XNUC2 are available to Nakivo, we need to add XNUC3 to the inventory before we can start replication process.
I already covered this process in How to install (and configure) Nakivo article, so I will not be going through details about that here, be sure to check that article before you continue, it will help you successfully add your server to inventory.
After XNUC3 is added, we can continue further
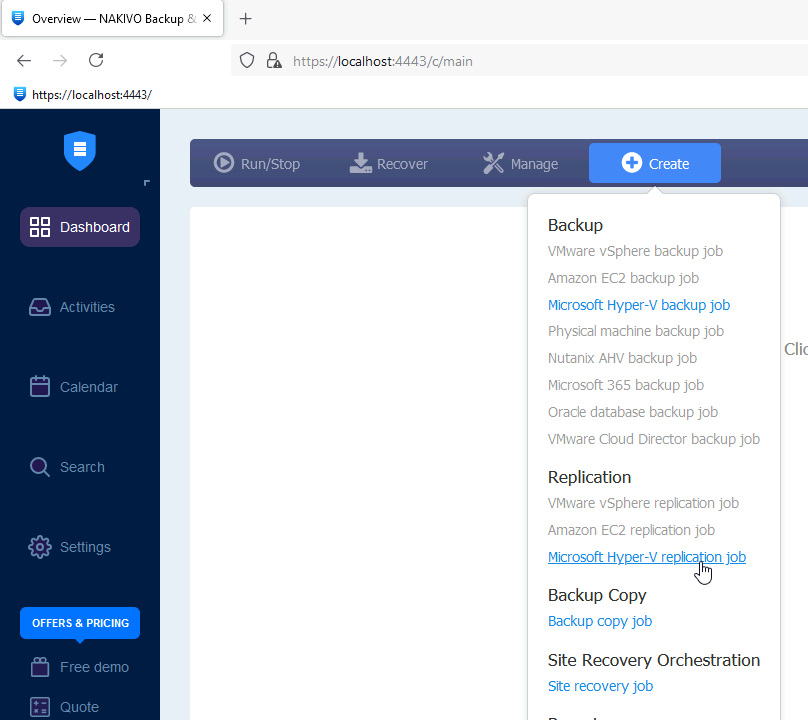
Ok, back to Dashboard menu | select Create | under Replication select Microsoft Hyper-V replication job
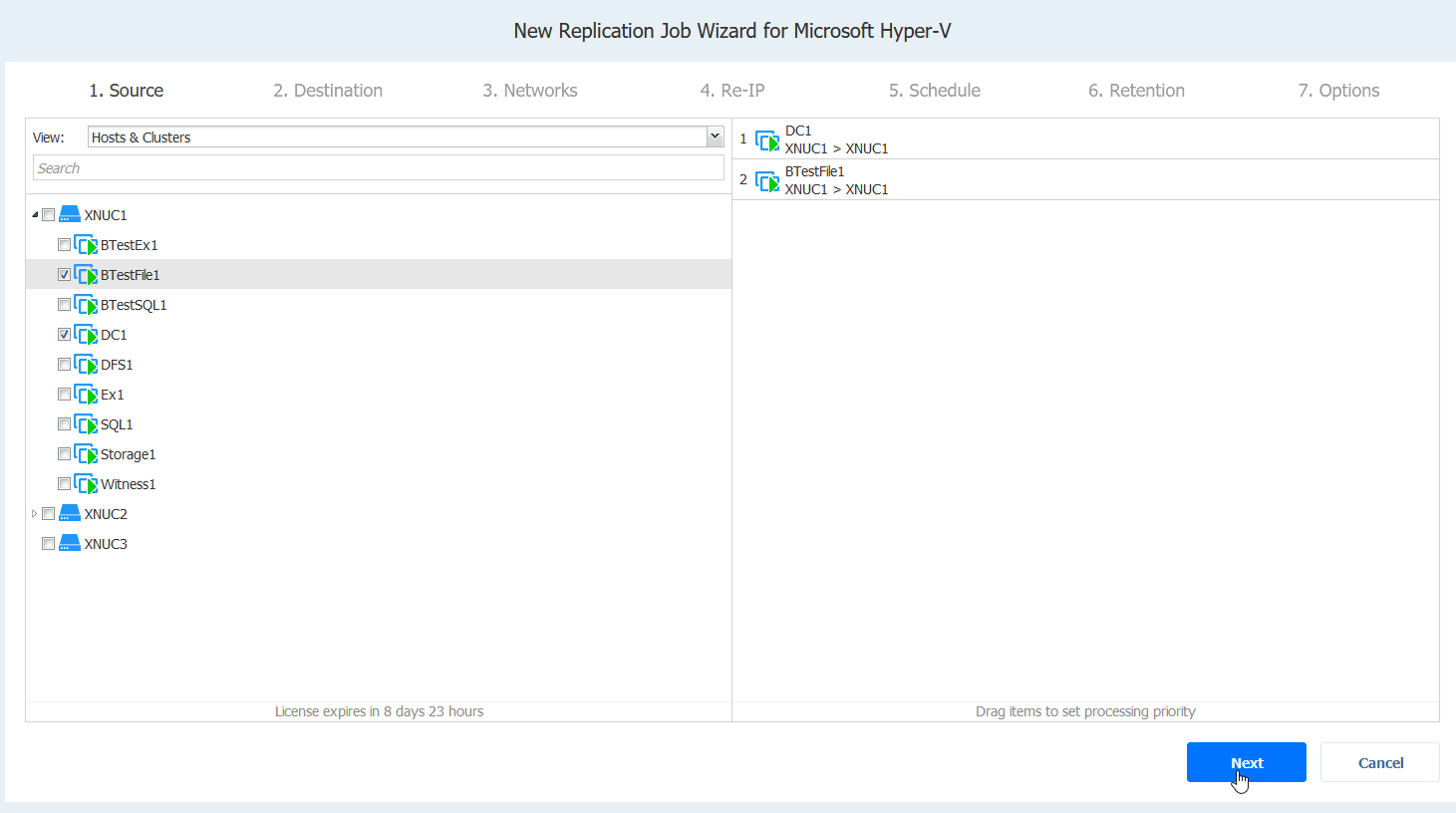
For this run we will select BTestFile1 (which is single machine, there is no cluster) and DC1. Later on I will add all the machines from the host to this replication job, so we can test it.
Next
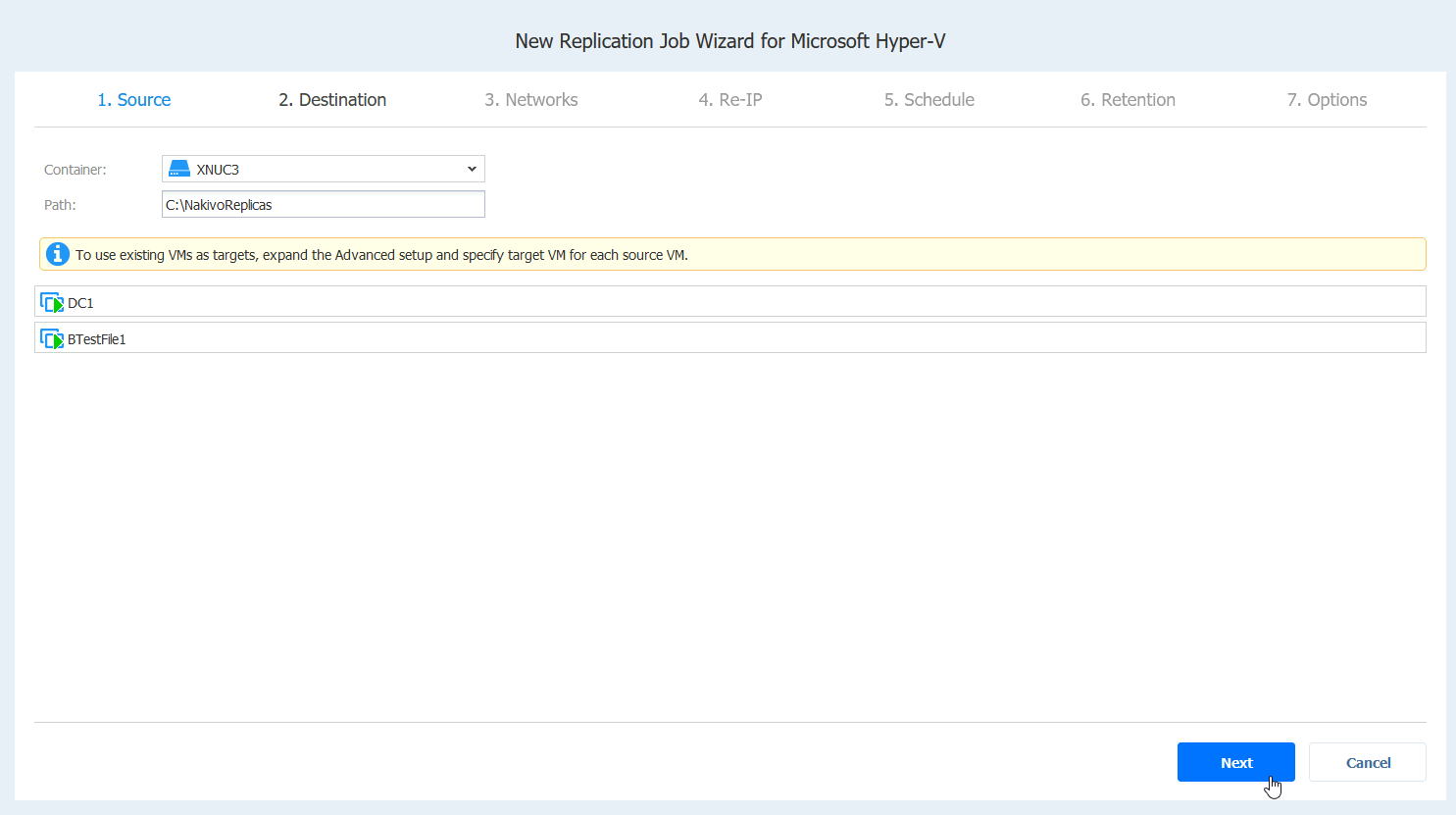
Under Destination we will select XNUC3 under container – I will leave default path and all the other details intact. Next
I will select enable network mapping. And click on Create new mapping. (In my case, mappings are automagically done, but still I will do the process in case you don’t see networks mapped).
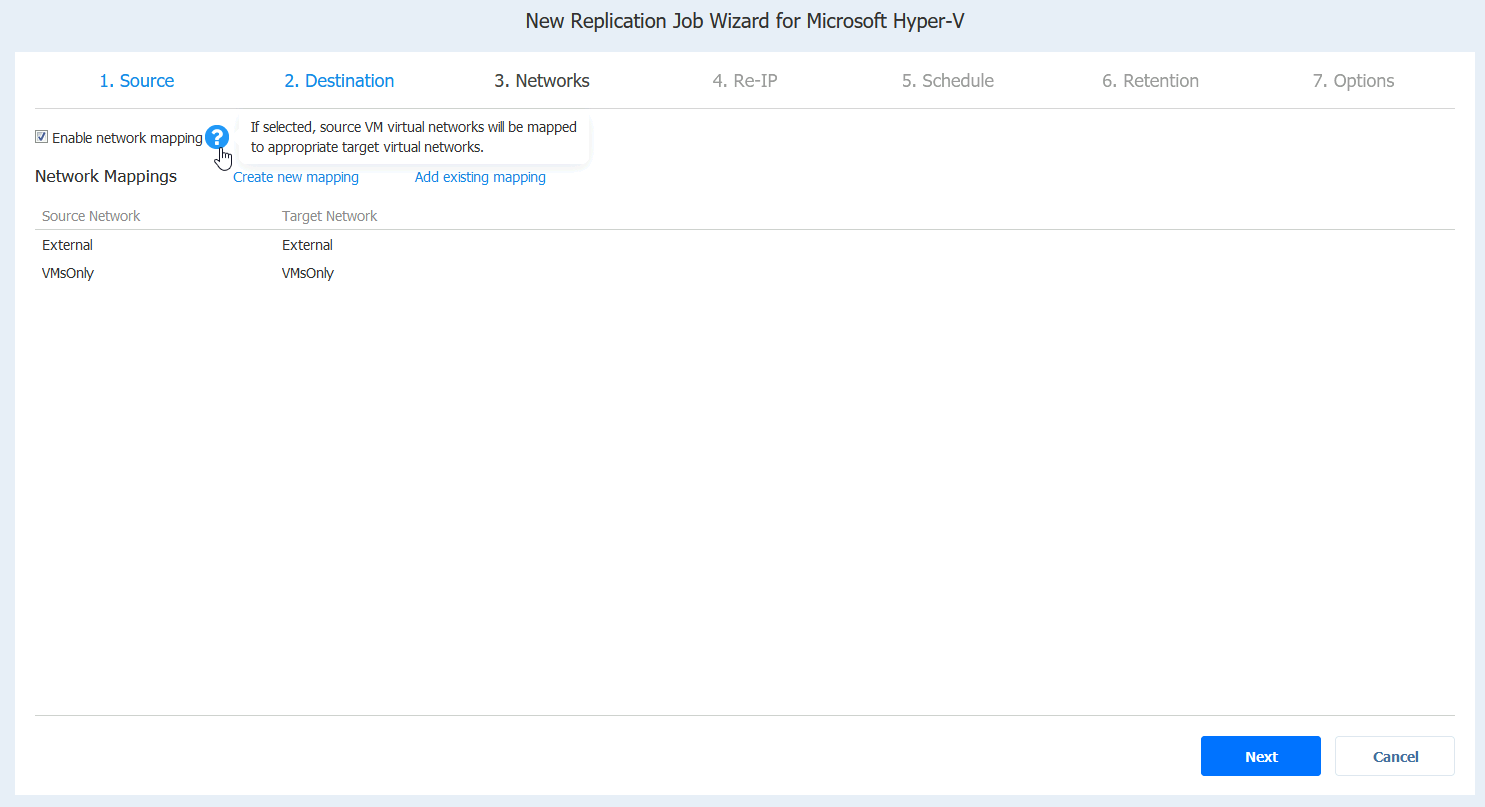
I will map External network from XNUC1 to External network on XNUC3 (these are networks configured in Hyper-V Manager | Virtual Switch Manager) and VMsOnly to VMsOnly.
Source network is External on XNUC1
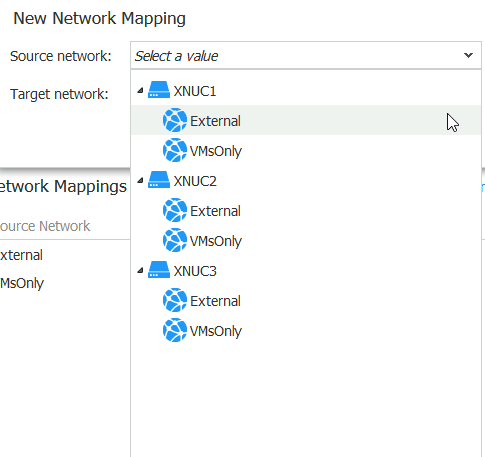
Target is External network on XNUC3
Save
Repeat for other networks if you have them.
I’m done with my mappings – Next
I will not be configuring Re-IP for this session, if you are interested to know more, I left a link below. Next
https://helpcenter.nakivo.com/display/NH/Replication+Job+Wizard+for+Hyper-V%3A+Re-IP
Schedule – completely up to you. Do you need periodically replication job (like in every few minutes) daily, weekly… It depends what your needs and workloads are. Next
Retention – again same story, set according to your needs.
I entered Job name, change app-aware mode to Enabled (fail on error) and left everything default in this job. However, I would recommend enabling VM verification for production needs. And everything else according to your preferences. Finish & Run
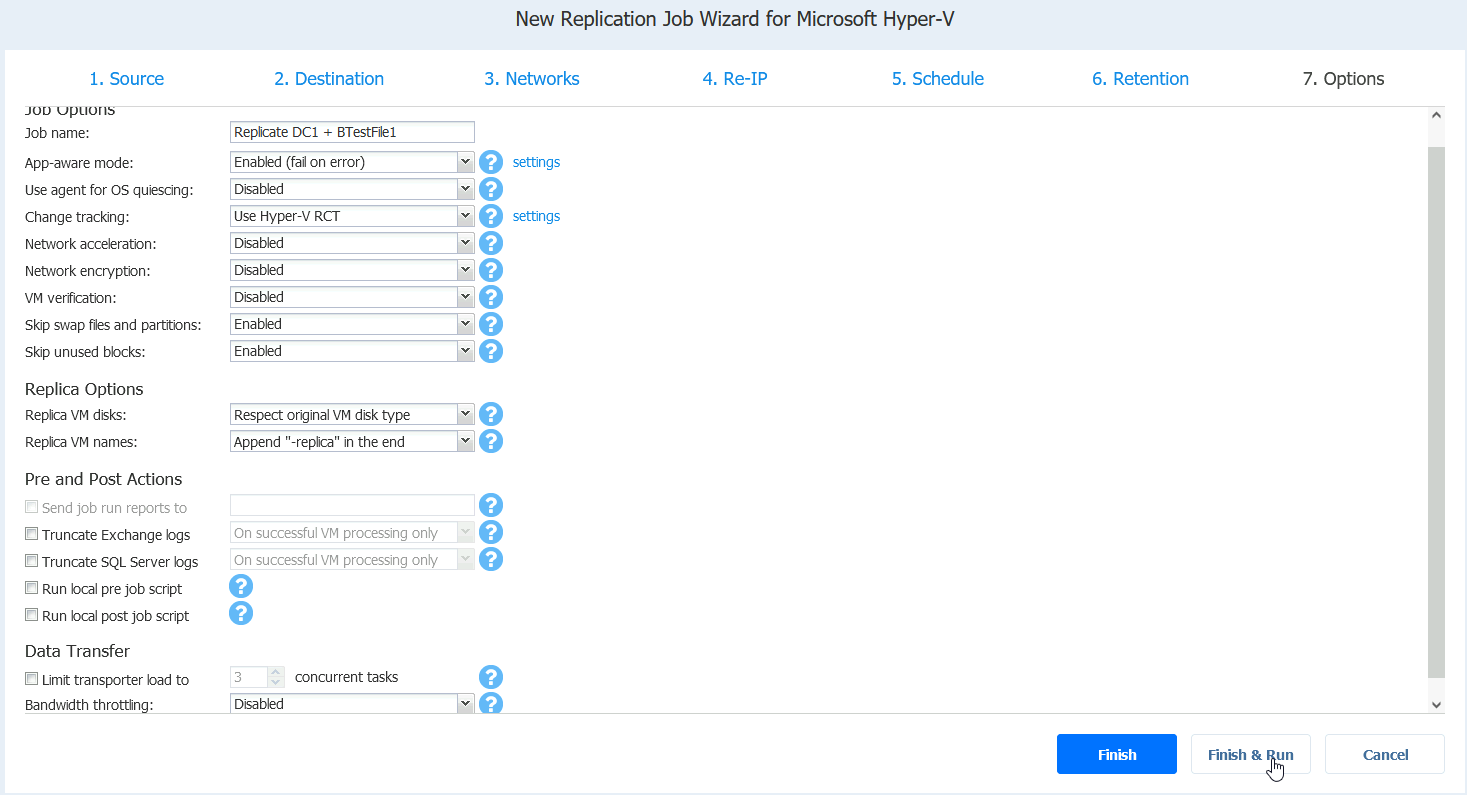
Run for selected VMs, select VMs – Run
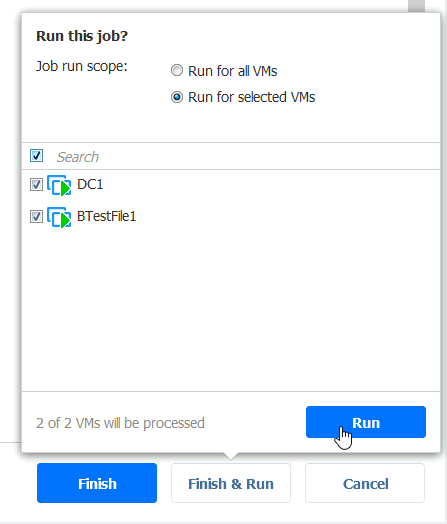
Under Activities we can see that the job started
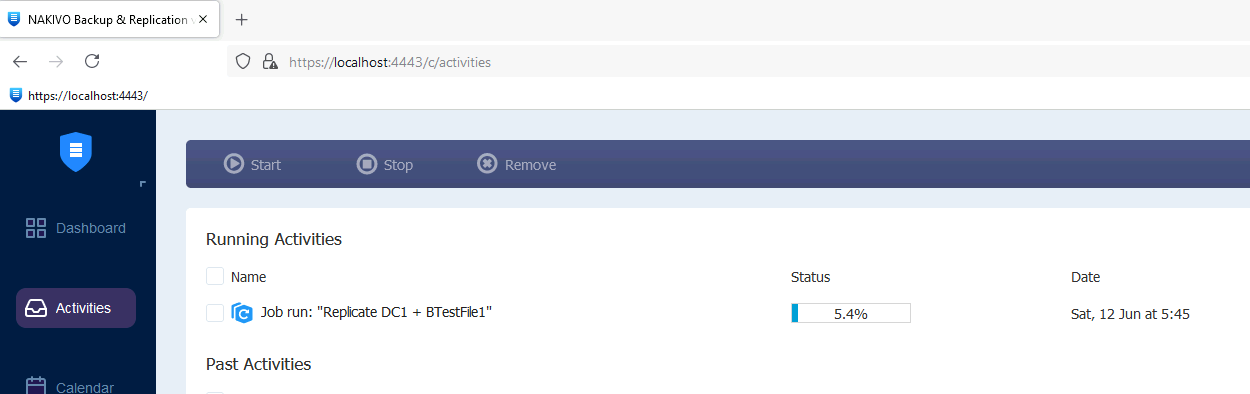
Also, I can see that these two machines appeared on XNUC3 machine
Job run was success!
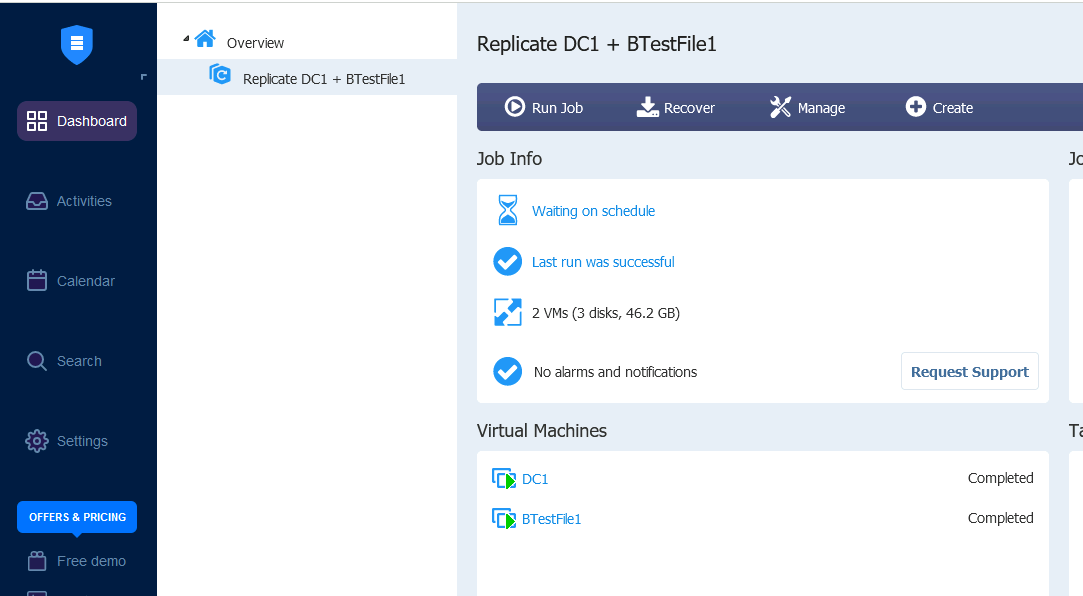
I will now create another few jobs where I will replicate DFS1, SQL1 and Ex1 machine. These machines have cluster services configured.
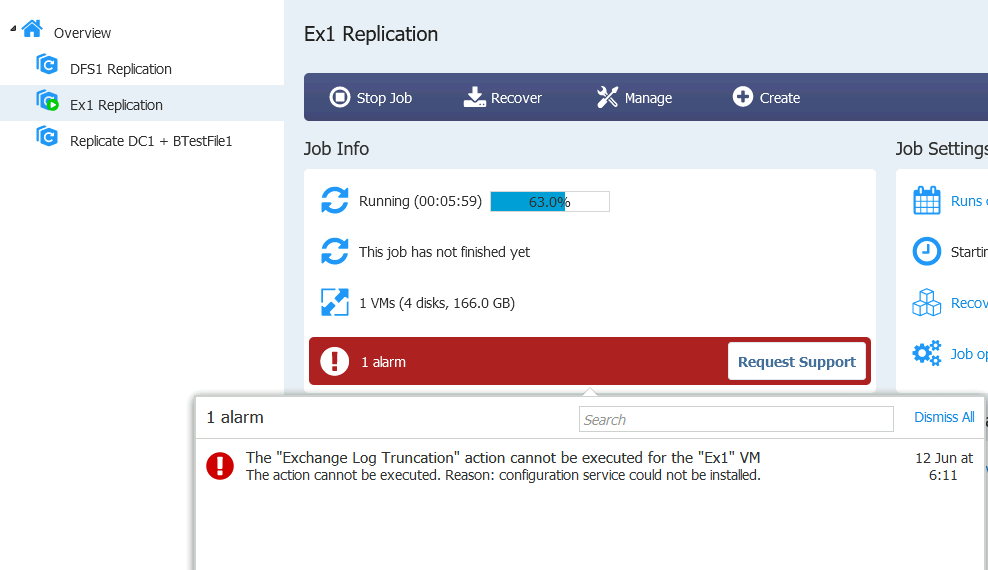
For the Exchange machine Replication job I also enable log truncation. I got error on that.
In real life, I have log truncation enabled only on backup jobs, but here I wanted to see what will happen.
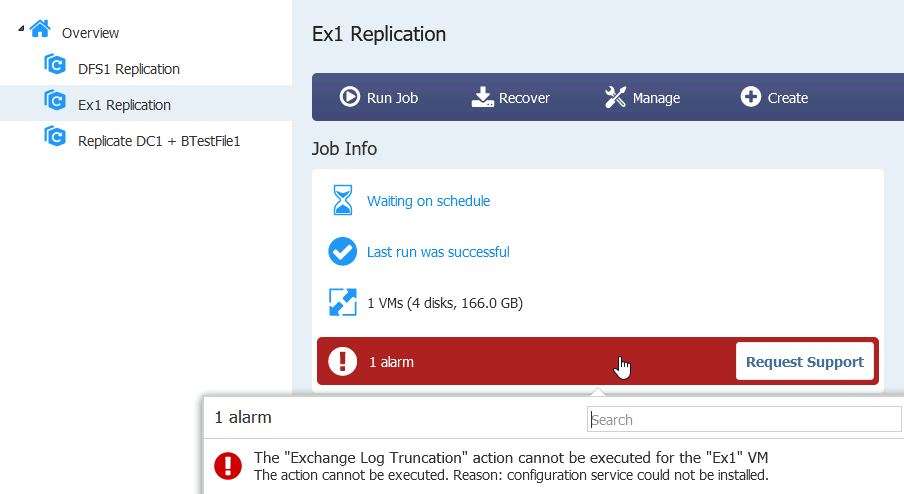
Replication job finished with success, log truncation is not essential part of the backup/replication.
I also done SQL and Storage (Storage Replica + ISCSI Target) VMs replication jobs.
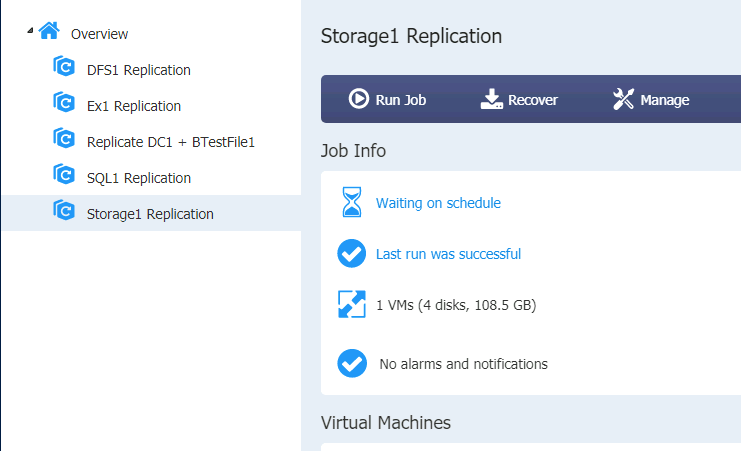
All machines are created on XNUC3 – powered down and waiting for the action.

Ok, we are done with the replication configuration. We will now test failover.
Failover to Hyper-V Replica (XNUC3)
I will simply turn off XNUC1. That will simulate failure of the server.
We were notified that XNUC1 is down, so we need to recover services that were active on that server.
I will first select DC1 and BTestFile1 job. DC1 is Active Directory and is essential for our domain, and BTestFile1 is file server which has only one node, and was only only available on XNUC1 server.
Ok, click on Dashboard in Nakivo, select your replication job (I will select Replicate DC1 + BTestFile1 job | Select Recover | VM replica failover
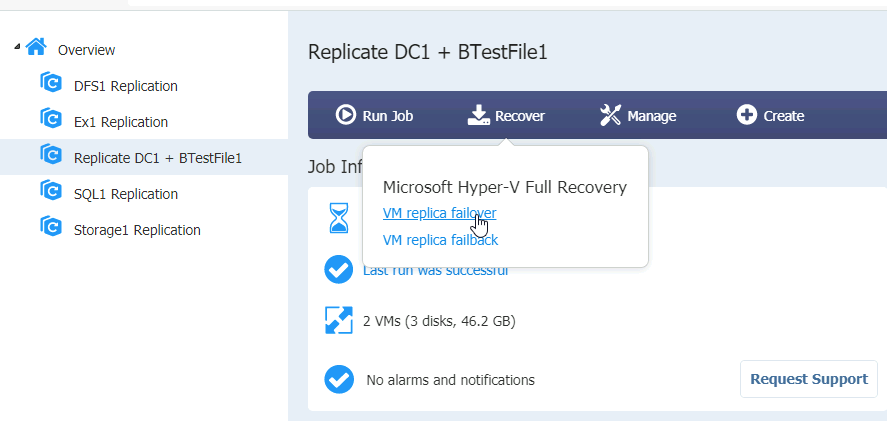
Select machines you wish to failover
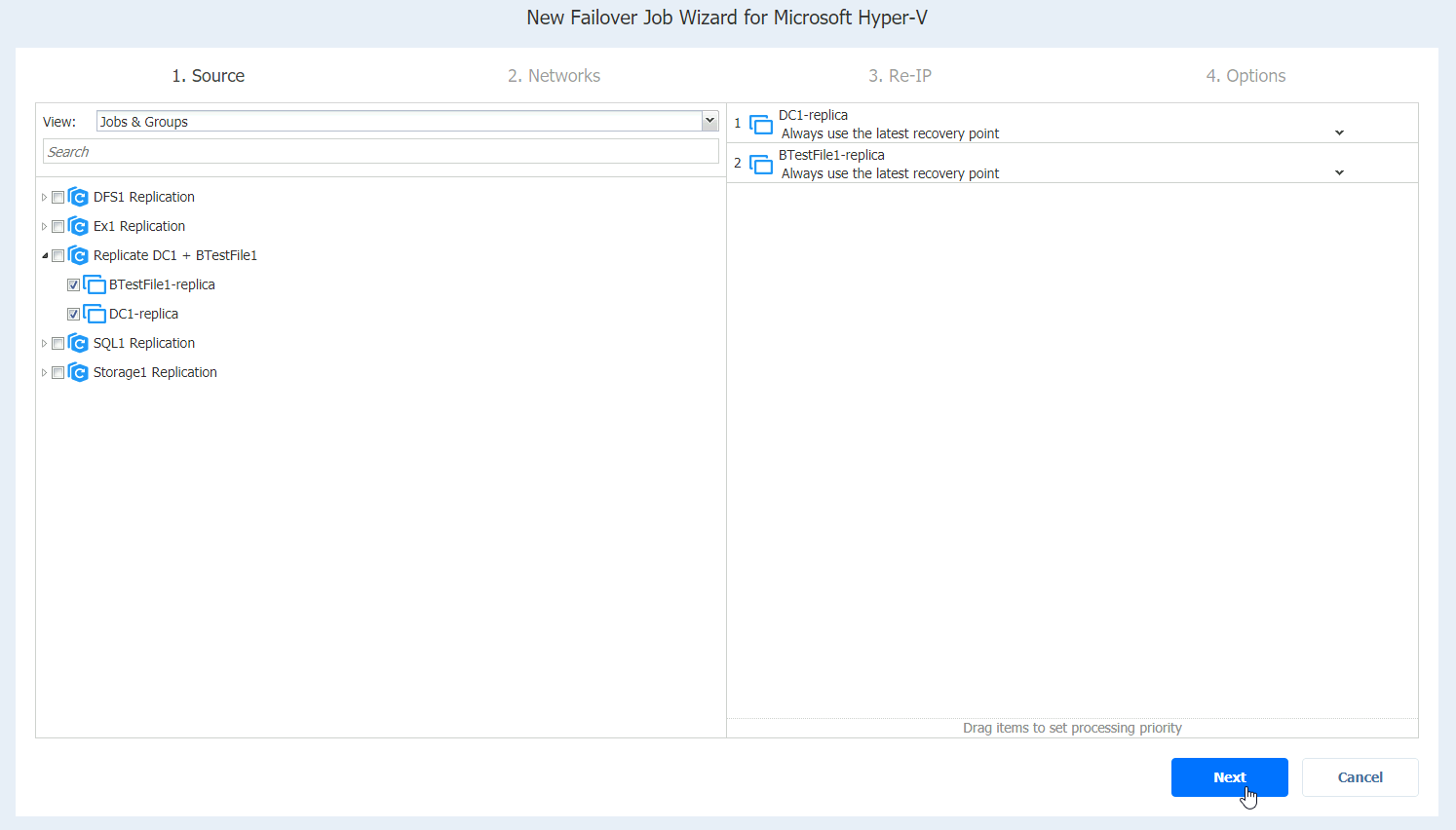
I will enable network mapping. Next
I haven’t enable RE-IP, so I will skip it. Next
Name your job, I will also uncheck “Power off source VMs” since server is down. Finish & Run
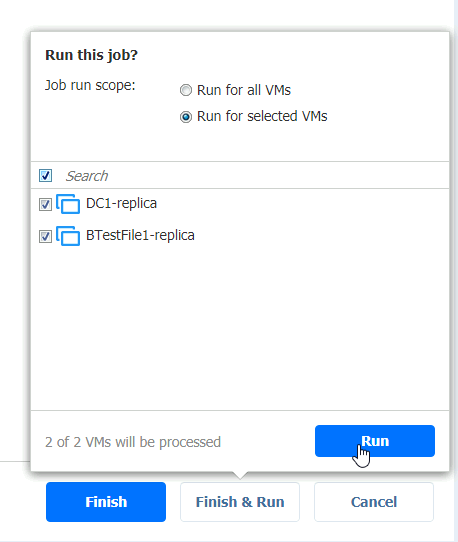
Hoping for the best…
Job is done very quickly
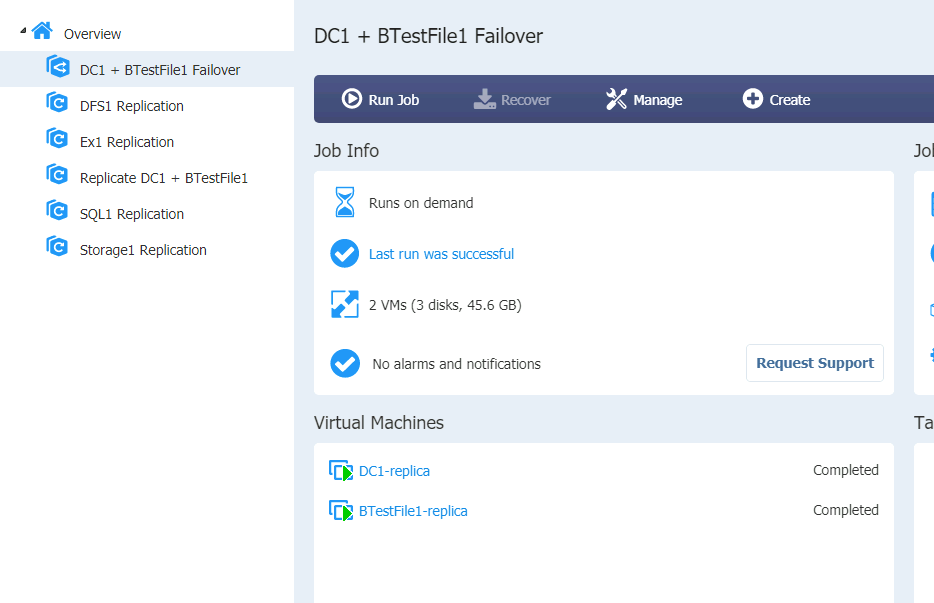
Machines are running
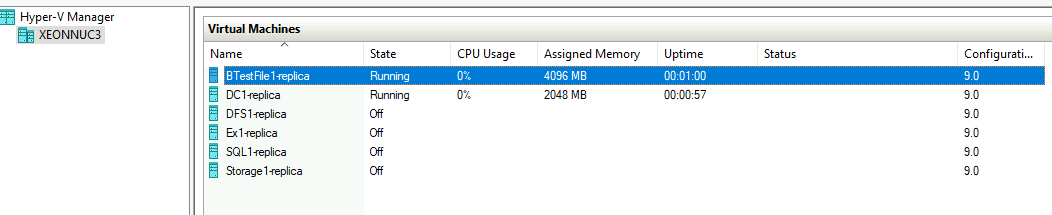
I left DC2 to ping DC1 to see when it becomes available.
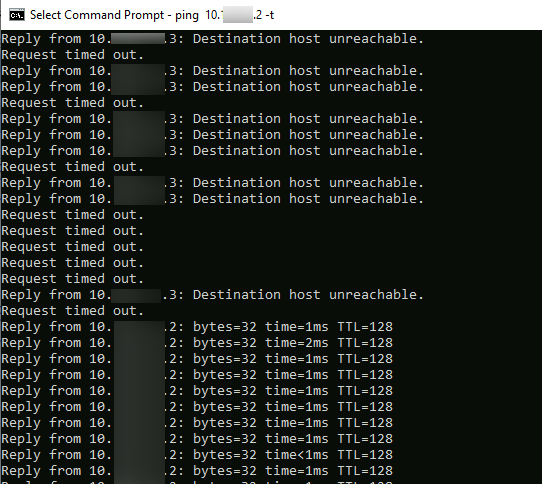
Everything is as it should be on machine that are recovered to another server. Network settings, setup…
I have done this procedure on other machines…
All the machines did well
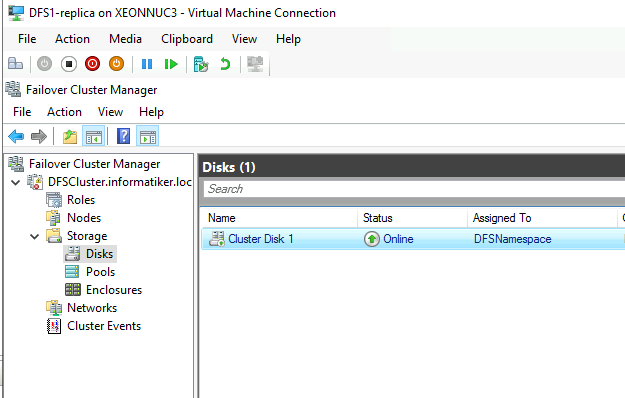
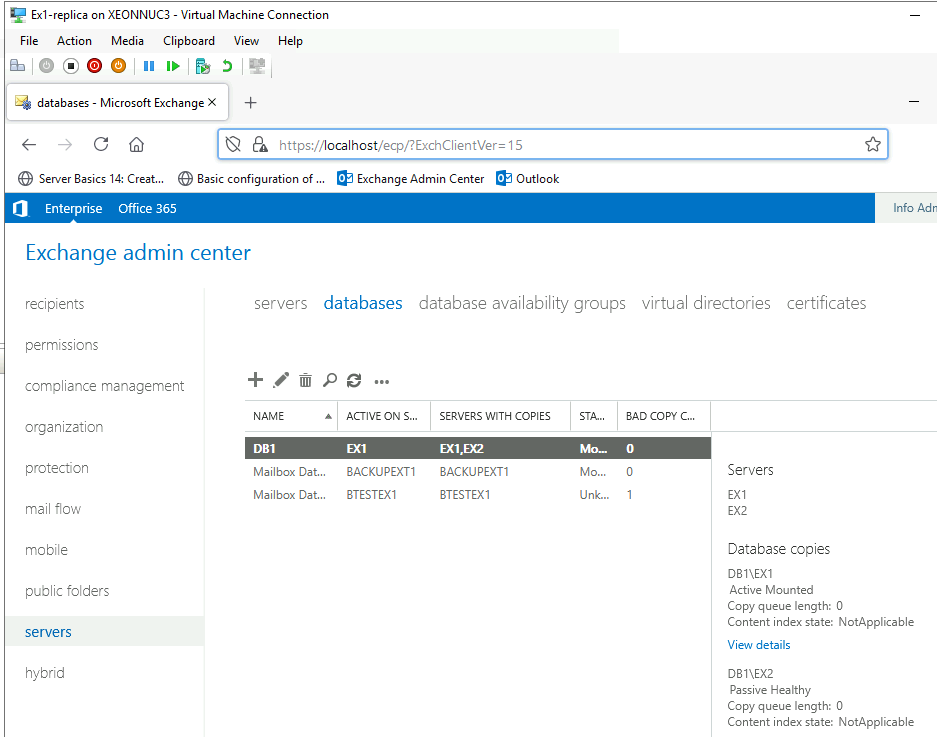
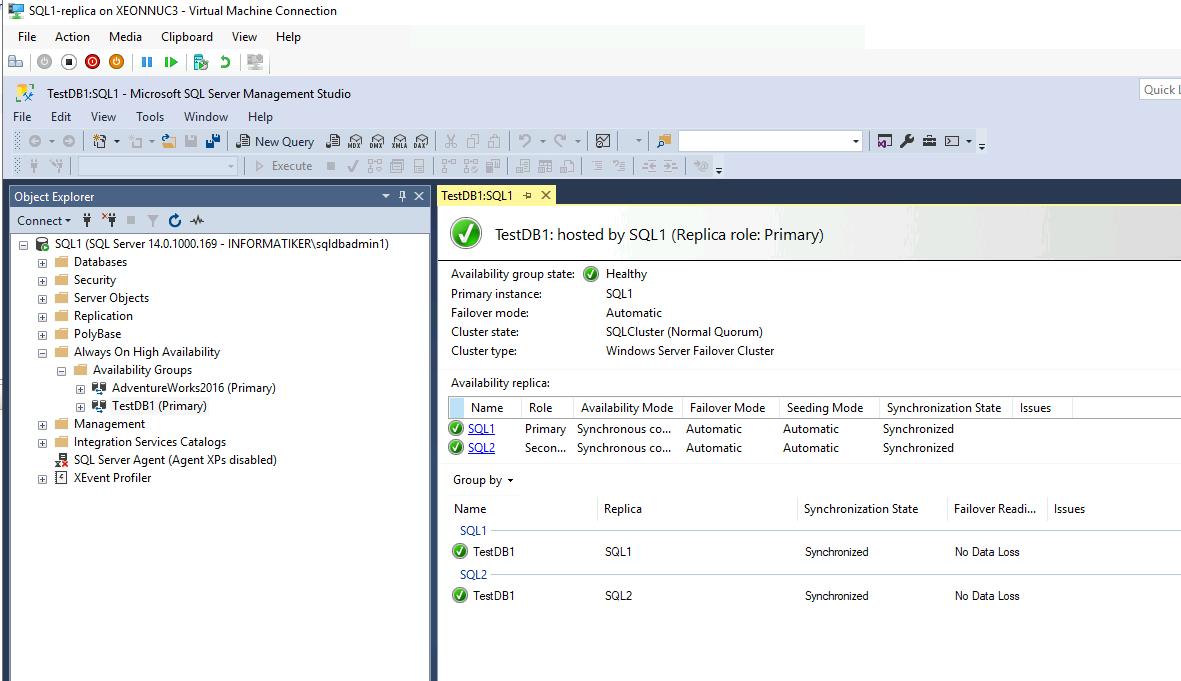
Storage1 Failover and Failback is done without App-Aware state…
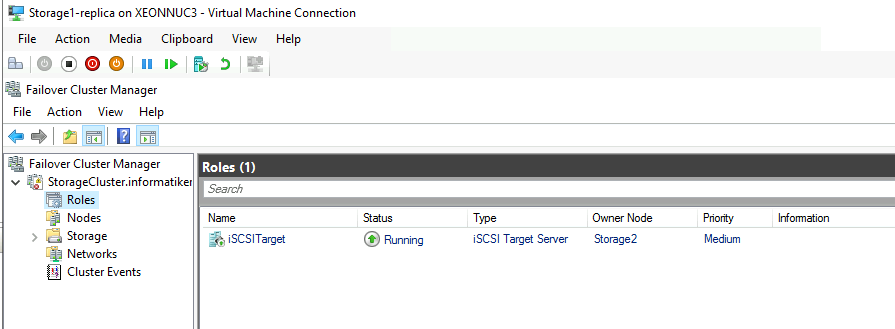
We can say that our environment works without an issue after we done Failover to XNUC3 and XNUC1 went down. That is great.
Failback to the XNUC1
Let’s say we managed to bring back up our primary server XNUC1 with VMs intact. We have machines on XNUC1 that are powered off, and VMs are currently active on our XNUC3. Lets; fail them back. This scenario will update/replace VMs with the ones we have currently active.
This is current state of the XNUC1. At one point my XNUC1 rebooted, when it did so – it came back up with all the machines powered up!! So, I had same machines powered up at XNUC1 and at XNUC3 at the same time. I quickly powered them down… Why I’m writing this, you’ll see further down the line.
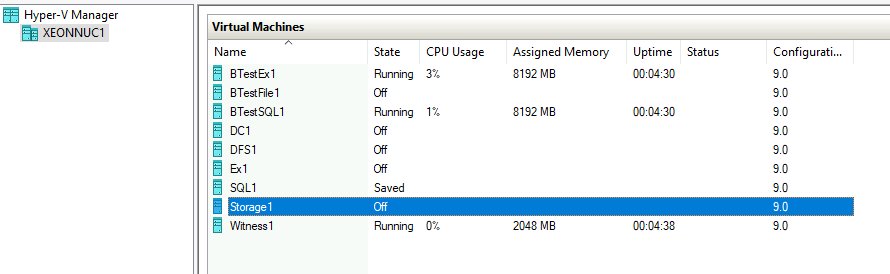
All machines are working on XNUC3.
Let’s go to our Nakivo Management console.
We first need to refresh inventory and see if Transporter works on XNUC1
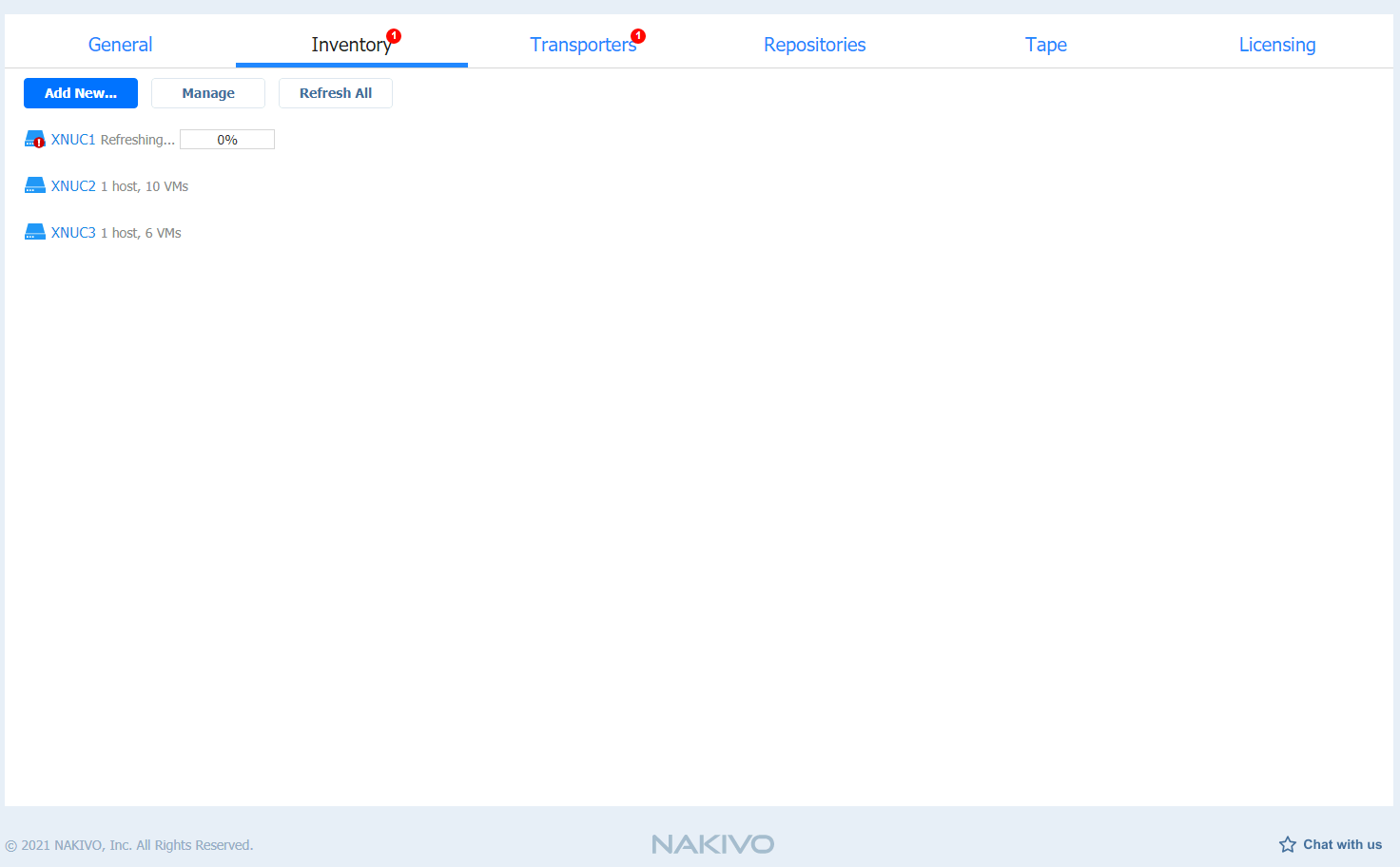
After you are sure that all transporter are in order, we can proceed further.
I will firstly select Replication job for the DC1 and BTestFile1, select Recover | VM replica failback
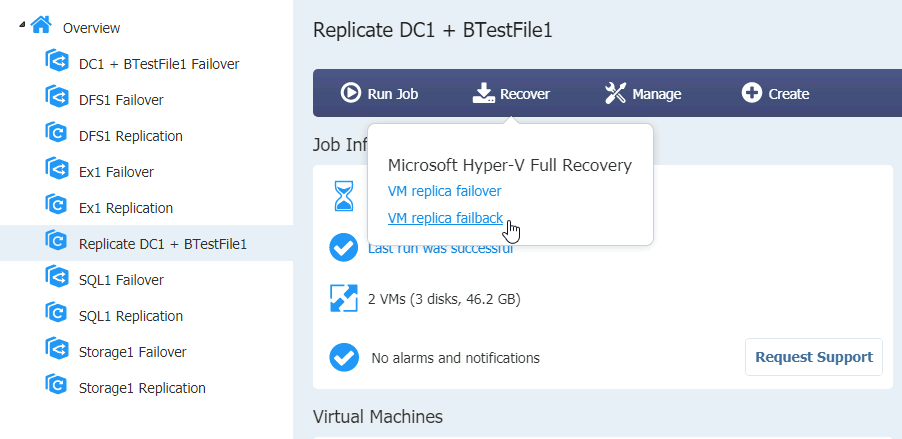
Select VMs you wish to failback | Next
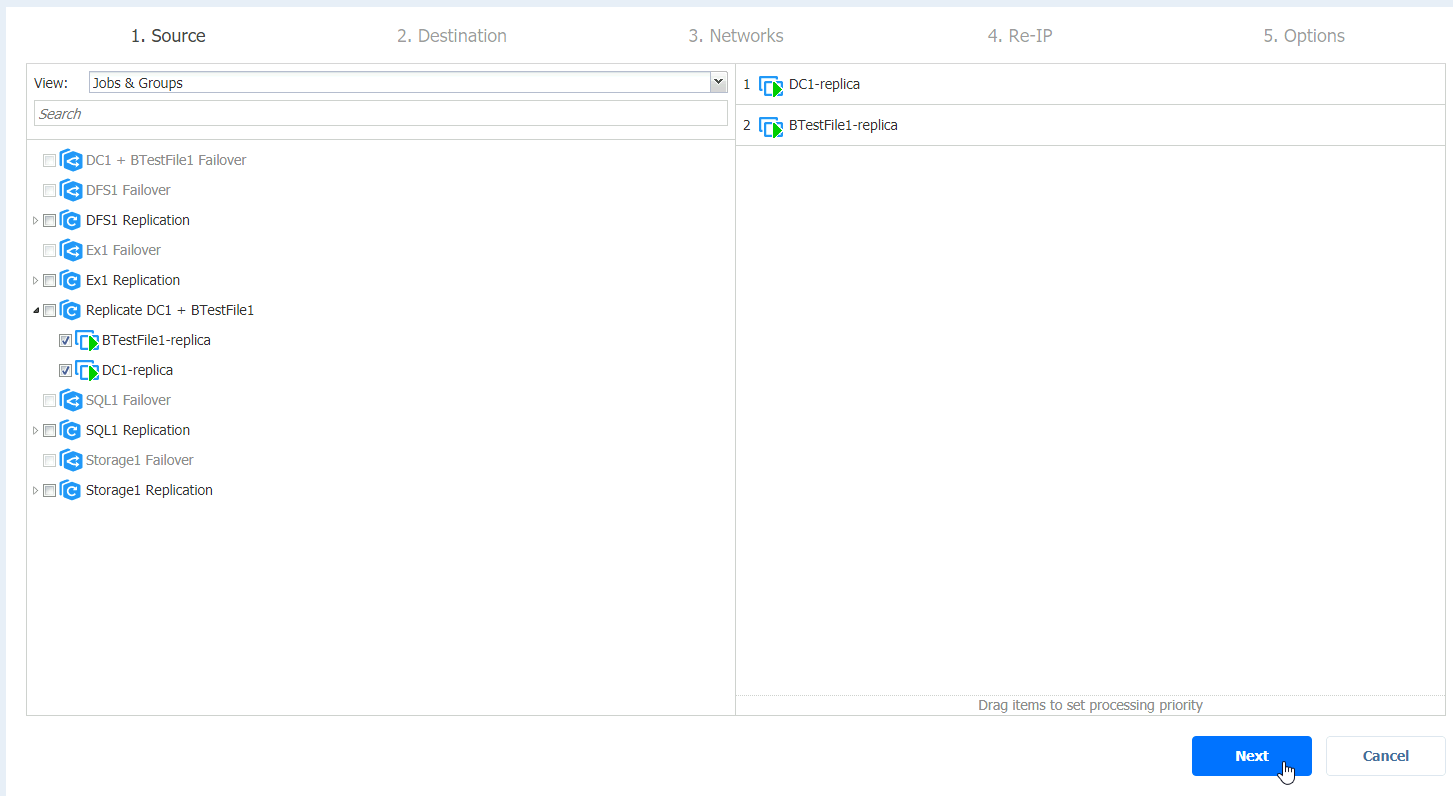
We will failback to original location | Next
That option will update replace existing VMs in original location.
Again, we will enable network mapping | Next
I will not enable RE-IP | Next
I will name Failback job, select app-aware mode as enabled, and select to power-off replica VMs. Finish & Run
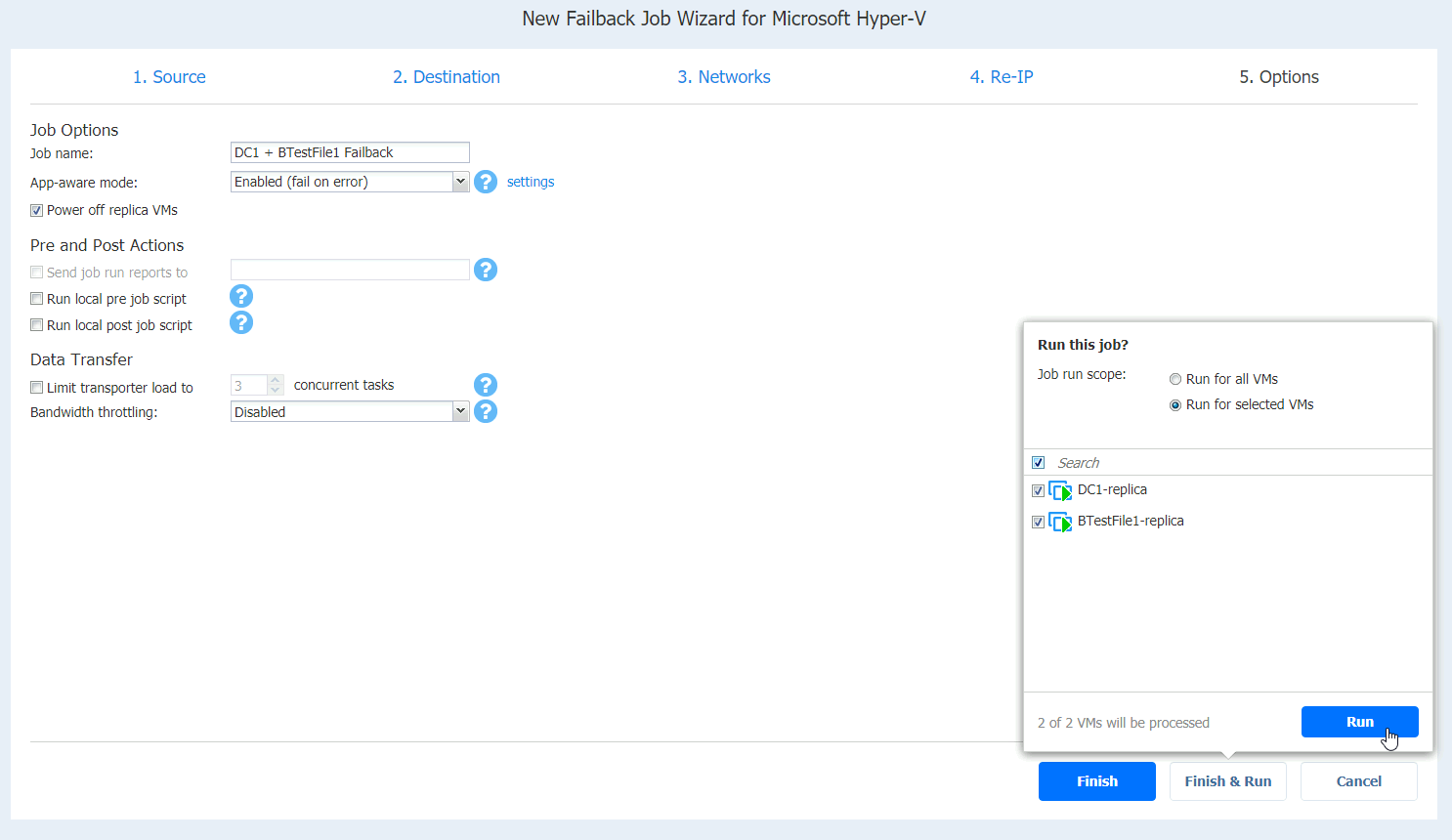
Job is running, and I can see status inside Hyper-V Manager on XNUC1
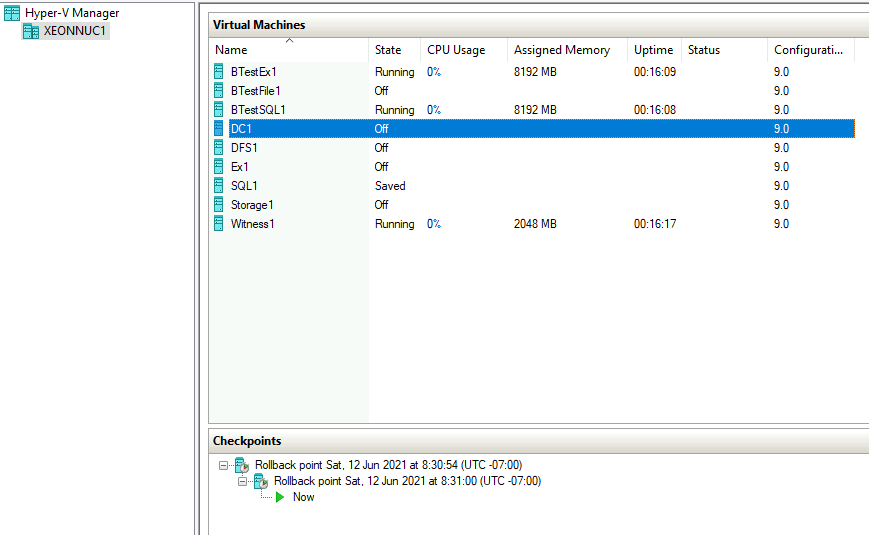
Job is done
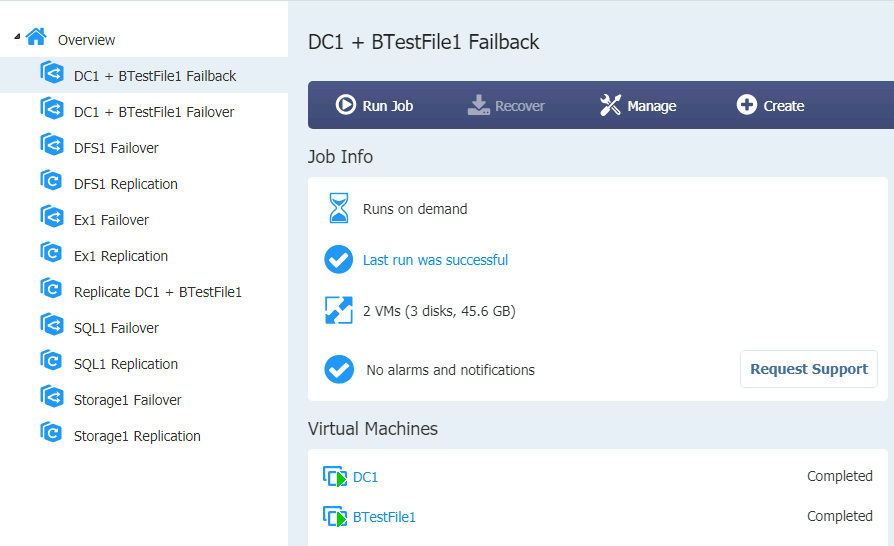
Machines on the XNUC1 should be automatically started after Failback and machines on XNUC3 are turned off after Failback was done.
These are results for other VMs
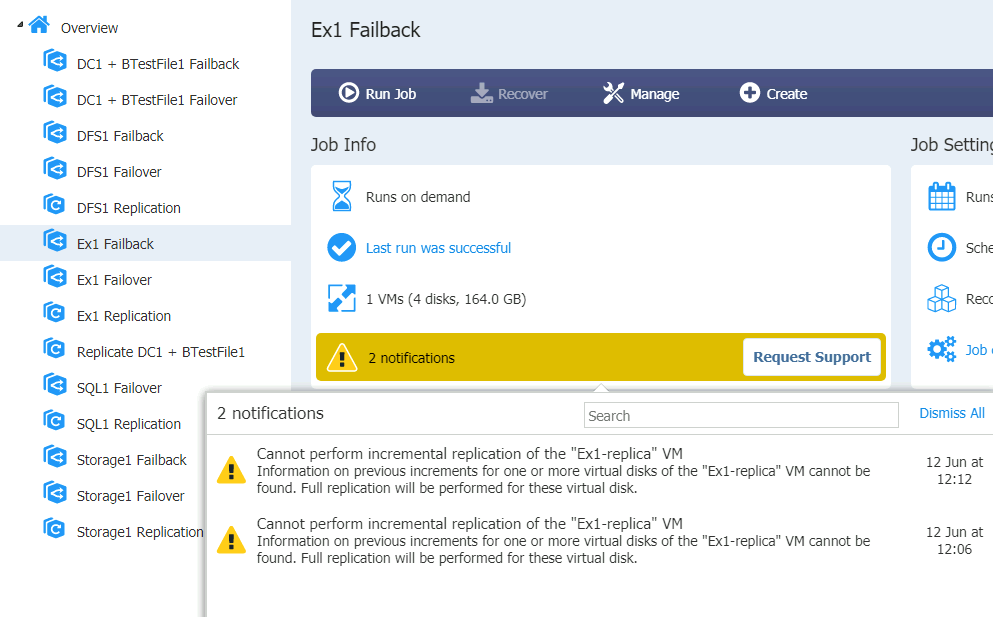
Ex1 Failback
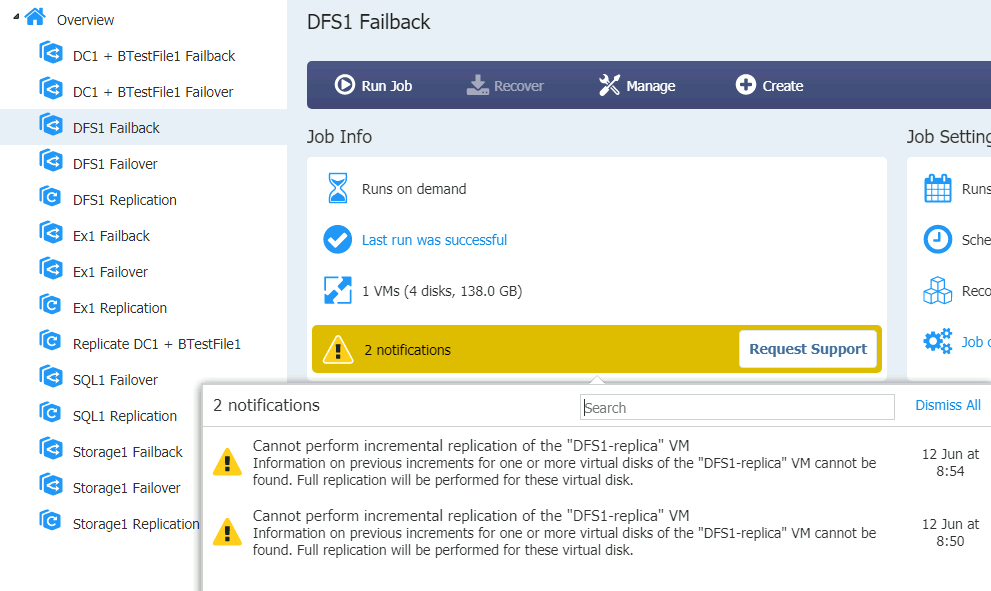
DFS1 Failback
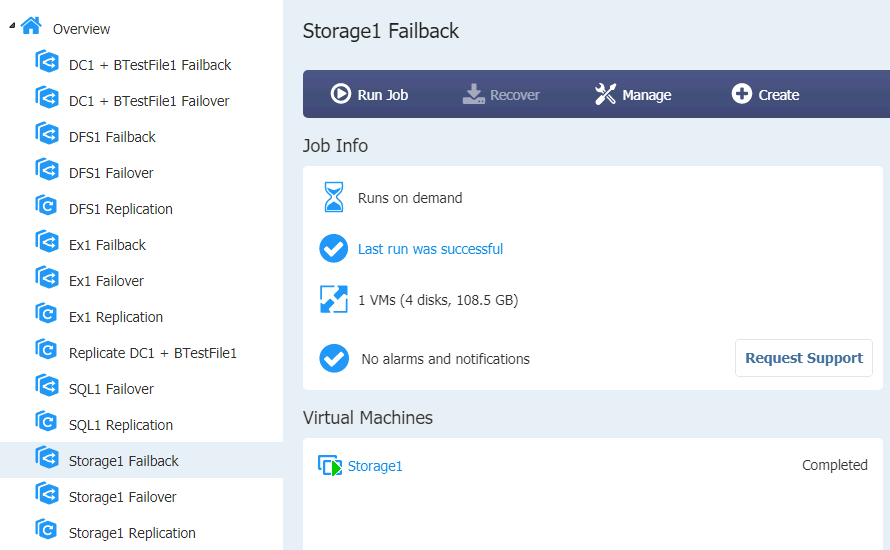
Storage1 Failover and Failback is done without App-Aware state…
Ok, so all the jobs finished with success. Machines on the XNUC3 are turned off, and the ones on XNUC1 are turned on.
Machines themselves have not fared fall on Failback.
DC1 didn’t want to boot
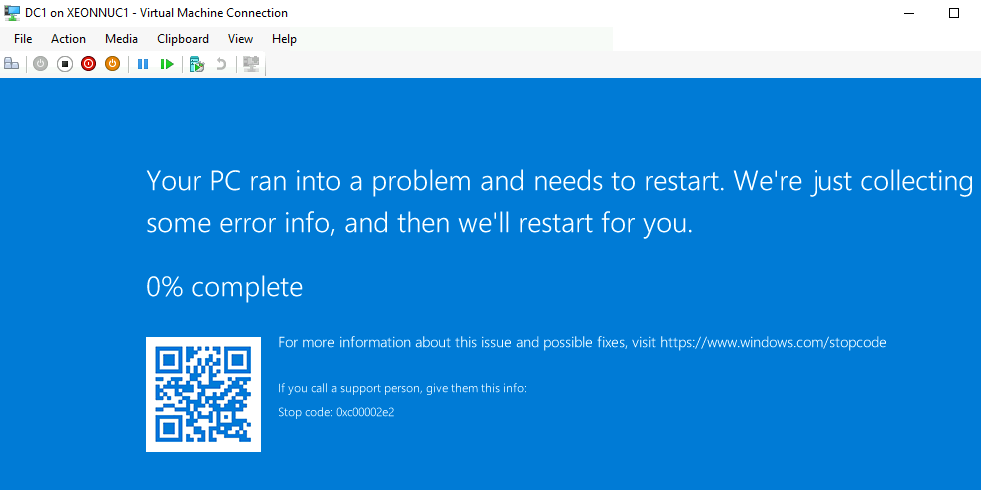
DFS1 had some boot problems
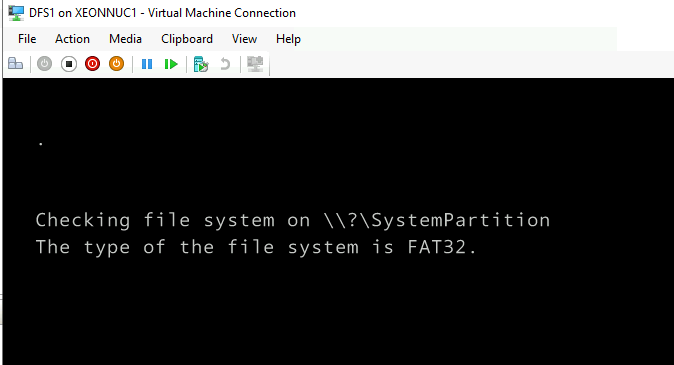
Also, some services don’t work after I booted it again.
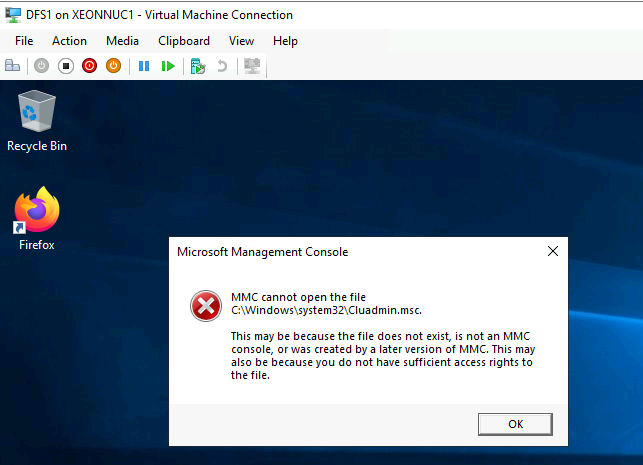
DFS works ok, files are intact and replicating to DFS2, but MMC is not working, AV solution is corrupted…
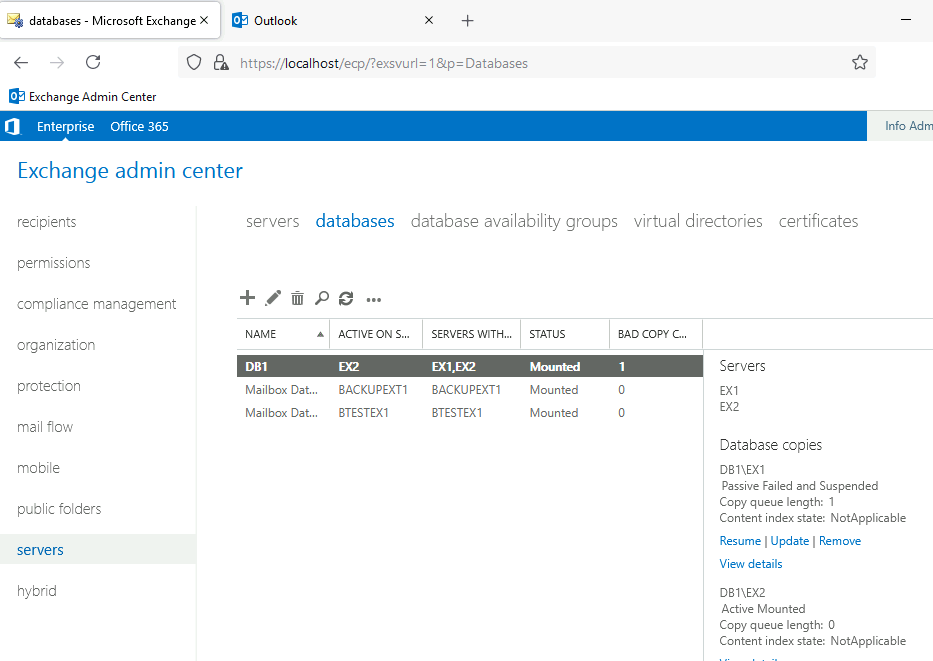
Ex1 (Exchange) is also in rough shape after Failback, DB does not want to mount, I’m unable to open Exchange Active Center on Ex1. All the Exchange services are up on Ex1
Storage1 (Storage Replica with ISCSI Target) is recovered as image, without APP-Aware option in Nakivo. It failed back without problems.
SQL1 haven’t failed back in the end, because I couldn’t brought it up from saved state on XNUC1.
So, what is conclusion with FailBack? As I mentioned in the beginning of FailBack part – part of the machines turned on after XNUC1 was brought up. So, at some point I had two exact VMs off same type on network – two DC1 VMs (two ADs with same IP, config…), two DFS1 machines, two EX1 machines. Machines on XNUC1 and XNUC3 where powered up at the same time.
However, I powered down all VMs on XNUC1 and only THEN started Failback from XNUC3. In that process, all VMs after Failback from XNUC3 shut down VM on XNUC3 and powered up one on the XNUC1. So, that process went ok.
Could I also in reality have some problems with XNUC1? Perhaps yes. I really don’t power down VMs after I shut down Hyper-V host. I let Hyper-V does that job for me.
So, I noticed that from time to time, machines in my LAB (especially on XNUC1) are stuck in saved state – I need to delete configuration and recreate VM – only then will it work.
Hyper-V or hardware problem – I really don’t know.
In the end, could it be Nakivo’s fault for these weak failback results? It could be, it could be that it just haven’t done its job as it should. I wrote all text above, so that you know what other environmental problems I have in this LAB. As I already mentioned, this is a fresh lab, on fairly new hardware, and all is done just for Nakivo testing.
I’ve done this in the past with Nakivo, and it worked well, but today, in this lab with Nakivo v.10.3 – Failback worked poorly.
Conclusion
While Failover job worked flawlessly, Failback had poor execution. I tried to describe everything that is going on in the environment I tested Nakivo Failback, so maybe guilt can be shared on all the parts of this equation (hardware, hypervisor, backup softver) But, I tend to believe that Nakivo didn’t do well with Failback.
Does that mean Nakivo cannot be used for Disaster Recovery? Absolutely no – I done this in the past and it worked ok, today, in this lab it didn’t – and I feel obliged to describe results as they are, because there are different production scenarios everywhere, and if this happened in lab, it also might happen to someone else in some other scenario.
You can simply use Replication and Failover your machines and then fail them back manually to your primary server.
There are many ways you can get around this issue. So, my takeaway from this is – test solution for yourself, and see how it fits into your environment, and what problems you have (if any) with it and decide for yourself.
For me, Failback problems are not deal breaker, especially, since I had this part work for me in the past many times.